我想写:
assert np.all(0 < a < 2)
当我尝试使用a作为numpy数组时,却发现它无法工作。你有没有更好的写法?
numpy.logical_and 来实现:>>> a = np.repeat(1, 10)
>>> np.logical_and(a > 0, a < 2).all()
True
&。>>> ((0 < a) & (a < 2)).all()
True
import numpy as np
def between_all_and(arr, a, b):
return np.all((arr > a) & (arr < b))
或者:
import numpy as np
def between_and_all(arr, a, b):
return np.all(arr > a) and np.all(arr < b)
或者等价地,通过调用np.ndarray.all()而不是np.all()来实现。
请注意,np.all()可以被all()替换,对于较小的输入可能更快,但在大型输入上速度要慢得多。
虽然它们给出相同的结果,但它们都具有次优秀的短路特性:
between_all_and()(“所有and”)将在访问短路代码之前计算arr > a和arr < b数组(np.all())between_and_all()(“所有的and”)在执行所有arr > a测试之前不会在arr < b上短路。在随机分布的数组上,这意味着这两者的时间可能非常不同。
或者,可以使用基于循环的Numba加速实现:
import numpy as np
import numba as nb
@nb.njit
def between_all_nb(arr, a, b):
arr = arr.ravel()
for x in arr:
if x <= a or x >= b:
return False
return True
这种方法具有更好的短路特性,并且不会创建潜在的大型临时数组。
根据@NeilG的评论,我还提供了一个加速版的jax版本。
import jax
import jax.numpy as jnp
@jax.jit
def between_and_all_jax(arr, a, b):
return jnp.all((arr > a) & (arr < b))
我们可以对包含随机数的数组(大小为n)进行批处理(大小为m),以获得哪些方法更快,并且速度提升了多少的一些想法。
事实上,假设一个均匀分布于 [0, 1] 范围内的数组,如果检查不同的范围,则可能会出现不同的短路情况:
这些基准测试使用如下命令生成:
import pandas as pd
import matplotlib.pyplot as plt
def benchmark(
funcs,
args=None,
kws=None,
ii=range(4, 24),
m=2 ** 15,
is_equal=np.allclose,
seed=0,
unit="ms",
verbose=True
):
labels = [func.__name__ for func in funcs]
units = {"s": 0, "ms": 3, "µs": 6, "ns": 9}
args = tuple(args) if args else ()
kws = dict(kws) if kws else {}
assert unit in units
np.random.seed(seed)
timings = {}
for i in ii:
n = 2 ** i
k = 1 + m // n
if verbose:
print(f"i={i}, n={n}, m={m}, k={k}")
arrs = np.random.random((k, n))
base = np.array([funcs[0](arr, *args, **kws) for arr in arrs])
timings[n] = []
for func in funcs:
res = np.array([func(arr, *args, **kws) for arr in arrs])
is_good = is_equal(base, res)
timed = %timeit -n 8 -r 8 -q -o [func(arr, *args, **kws) for arr in arrs]
timing = timed.best / k
timings[n].append(timing if is_good else None)
if verbose:
print(
f"{func.__name__:>24}"
f" {is_good!s:5}"
f" {timing * (10 ** units[unit]):10.3f} {unit}"
f" {timings[n][0] / timing:5.1f}x")
return timings, labels
def plot(timings, labels, title=None, xlabel="Input Size / #", unit="ms"):
n_rows = 1
n_cols = 3
fig, axs = plt.subplots(n_rows, n_cols, figsize=(8 * n_cols, 6 * n_rows), squeeze=False)
units = {"s": 0, "ms": 3, "µs": 6, "ns": 9}
df = pd.DataFrame(data=timings, index=labels).transpose()
base = df[[labels[0]]].to_numpy()
(df * 10 ** units[unit]).plot(marker="o", xlabel=xlabel, ylabel=f"Best timing / {unit}", ax=axs[0, 0])
(df / base * 100).plot(marker='o', xlabel=xlabel, ylabel='Relative speed / %', logx=True, ax=axs[0, 1])
(base / df).plot(marker='o', xlabel=xlabel, ylabel='Speed Gain / x', ax=axs[0, 2])
if title:
fig.suptitle(title)
fig.patch.set_facecolor('white')
应该被称为如下:
funcs = between_all_and, between_and_all, between_all_nb, between_and_all_jax
avg_timings, avg_labels = benchmark(funcs, args=(0.01, 0.99), unit="µs", verbose=False)
wrs_timings, wrs_labels = benchmark(funcs, args=(-1.0, 2.0), unit="µs", verbose=False)
bst_timings, bst_labels = benchmark(funcs, args=(2.0, 3.0), unit="µs", verbose=False)
plot(avg_timings, avg_labels, "Average Case", unit="µs")
plot(wrs_timings, wrs_labels, "Worst Case", unit="µs")
plot(bst_timings, bst_labels, "Best Case", unit="µs")
要生成:
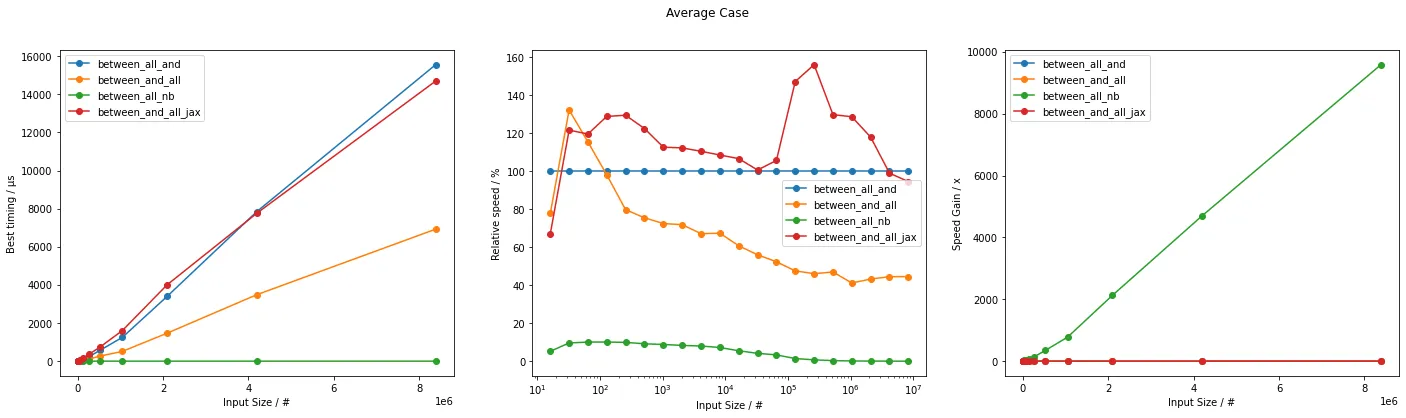
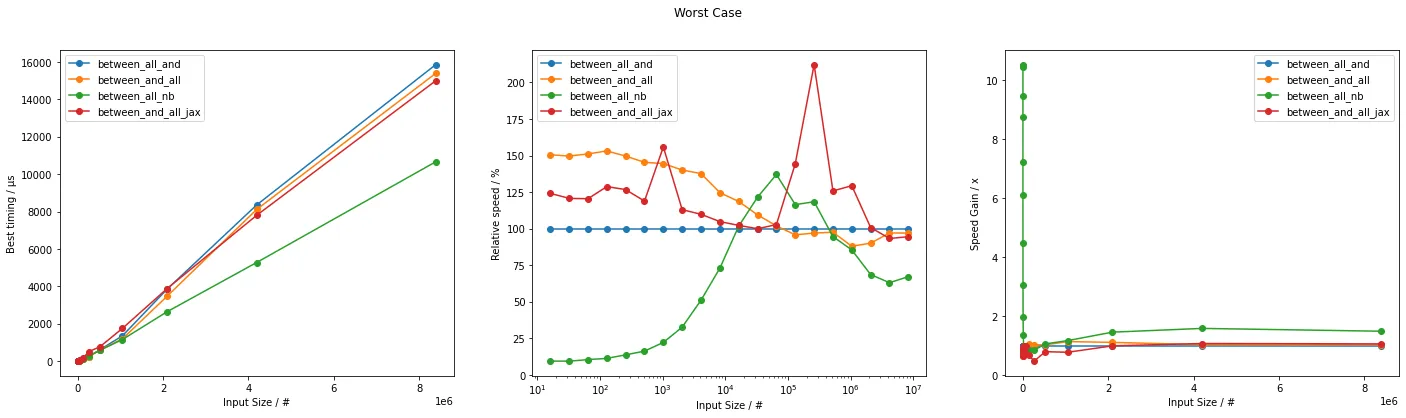
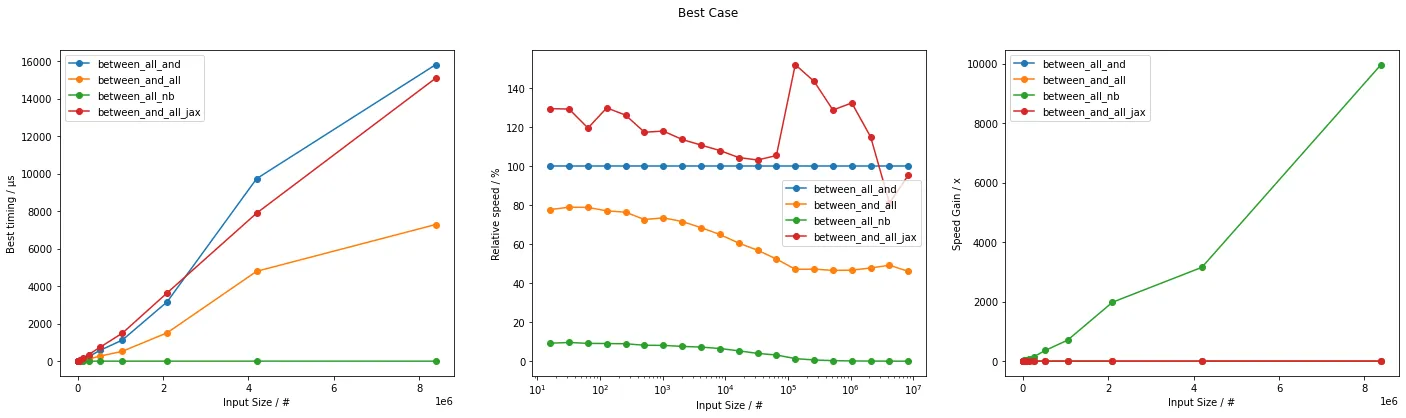
这些可以用来猜测哪个更快的情况下使用哪一个。
请注意,jax版本可能在用于测试的Colab笔记本上运行不够优化:
警告:absl:未找到GPU / TPU,回退到CPU。
通常,基于Numba的方法不仅效率最高,而且速度最快。
jax的版本吗?如果我只是用jax.numpy代替numpy,那么对于较小的输入,速度会变得更慢,而对于较大的输入,则会渐近地接近numpy。如果我添加@jax.jit,则会出现类型具体化错误。 - norok2@jax.jit def jax_version(arr, a, b): print("Compiling", arr.shape) return jnp.all((arr > a) & (arr < b)) - Neil Gand或者np.all而不是jnp。 - Neil Gand,抱歉。无论如何,我现在已经包含了你基于 jax 的版本。不幸的是,它似乎并不特别快,也没有针对短路进行优化。 - norok2
np.all()。 - norok2