我正在寻找一种最快的算法,将地图上的点按距离平均分组。k-means clustering algorithm 看起来直接且有前途,但无法产生大小相等的组。
是否有这个算法的变体或其他算法可实现所有聚类中成员数量相等?
是否有这个算法的变体或其他算法可实现所有聚类中成员数量相等?
如果有人想要复制和粘贴短函数,这里有一个 - 基本上运行KMeans,然后在最大分配点的约束下找到点与聚类之间的最小匹配(聚类大小)。
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
from scipy.optimize import linear_sum_assignment
import numpy as np
def get_even_clusters(X, cluster_size):
n_clusters = int(np.ceil(len(X)/cluster_size))
kmeans = KMeans(n_clusters)
kmeans.fit(X)
centers = kmeans.cluster_centers_
centers = centers.reshape(-1, 1, X.shape[-1]).repeat(cluster_size, 1).reshape(-1, X.shape[-1])
distance_matrix = cdist(X, centers)
clusters = linear_sum_assignment(distance_matrix)[1]//cluster_size
return clusters
who_is = np.tile(np.arange(n_clusters),(cluster_size+1))[:len(X)]
centers_repeated = centers[who_is]
distance_matrix = cdist(X, centers_repeated)
X_assignments = linear_sum_assignment(distance_matrix)[1]
clusters = who_is[X_assignments] - thepenguin77ELKI数据挖掘框架有一个等大小k-means教程。
这不是一个特别好的算法,但它是一种足够简单的k-means变体,可以编写教程并教人们如何实现自己的聚类算法变体。显然,有些人确实需要他们的簇具有相同的大小,尽管SSQ质量将比常规k-means差。
在ELKI 0.7.5中,您可以选择此算法作为tutorial.clustering.SameSizeKMeansAlgorithm。
总的来说,在理论上,将地图上的点按距离分组成相等大小的组是不可能的任务。因为将点分组成相等大小的组与按距离将点分组成簇是相互冲突的。
看这个图:
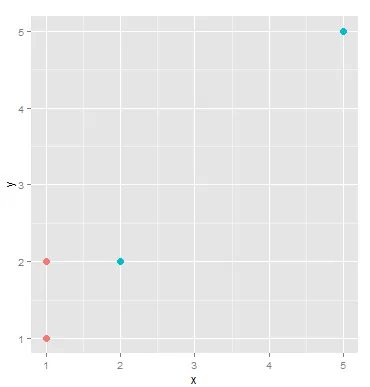
有四个点:
A.[1,1]
B.[1,2]
C.[2,2]
D.[5,5]
_labels_inertia_precompute_dense()。有一种更加简洁的后处理方法,给定聚类中心。假设有N个项目,K个群集和最大群集大小S = ceil(N/K)。
(item_id, cluster_id, distance)(item_id, cluster_id, distance):
cluster_id中的元素数量超过了S,则不执行任何操作item_id添加到群集cluster_id中。这个运行时间为O(NK lg(N)),应该会产生与@larsmans解决方案相当的结果,并且更容易实现。伪代码如下:
dists = []
clusts = [None] * N
counts = [0] * K
for i, v in enumerate(items):
dist = map( lambda x: dist(x, v), centroids )
dd = map( lambda (k, v): (i, k, v), enumerate(dist) )
dists.extend(dd)
dists = sorted(dists, key = lambda (x,y,z): z)
for (item_id, cluster_id, d) in dists:
if counts[cluster_id] >= S:
continue
if clusts[item_id] == None:
clusts[item_id] = cluster_id
counts[cluster_id] = counts[cluster_id] + 1
最近我需要为一个不太大的数据集实现这个功能。我的答案虽然运行时间比较长,但是它保证会收敛到局部极值。
def eqsc(X, K=None, G=None):
"equal-size clustering based on data exchanges between pairs of clusters"
from scipy.spatial.distance import pdist, squareform
from matplotlib import pyplot as plt
from matplotlib import animation as ani
from matplotlib.patches import Polygon
from matplotlib.collections import PatchCollection
def error(K, m, D):
"""return average distances between data in one cluster, averaged over all clusters"""
E = 0
for k in range(K):
i = numpy.where(m == k)[0] # indeces of datapoints belonging to class k
E += numpy.mean(D[numpy.meshgrid(i,i)])
return E / K
numpy.random.seed(0) # repeatability
N, n = X.shape
if G is None and K is not None:
G = N // K # group size
elif K is None and G is not None:
K = N // G # number of clusters
else:
raise Exception('must specify either K or G')
D = squareform(pdist(X)) # distance matrix
m = numpy.random.permutation(N) % K # initial membership
E = error(K, m, D)
# visualization
#FFMpegWriter = ani.writers['ffmpeg']
#writer = FFMpegWriter(fps=15)
#fig = plt.figure()
#with writer.saving(fig, "ec.mp4", 100):
t = 1
while True:
E_p = E
for a in range(N): # systematically
for b in range(a):
m[a], m[b] = m[b], m[a] # exchange membership
E_t = error(K, m, D)
if E_t < E:
E = E_t
print("{}: {}<->{} E={}".format(t, a, b, E))
#plt.clf()
#for i in range(N):
#plt.text(X[i,0], X[i,1], m[i])
#writer.grab_frame()
else:
m[a], m[b] = m[b], m[a] # put them back
if E_p == E:
break
t += 1
fig, ax = plt.subplots()
patches = []
for k in range(K):
i = numpy.where(m == k)[0] # indeces of datapoints belonging to class k
x = X[i]
patches.append(Polygon(x[:,:2], True)) # how to draw this clock-wise?
u = numpy.mean(x, 0)
plt.text(u[0], u[1], k)
p = PatchCollection(patches, alpha=0.5)
ax.add_collection(p)
plt.show()
if __name__ == "__main__":
N, n = 100, 2
X = numpy.random.rand(N, n)
eqsc(X, G=3)