我不确定为什么k-means聚类中可能存在重叠的聚类。从Chen(2018)的定义中,我看到以下内容:
"..将观测结果作为样本集分为K个不相交的簇"
然而,我在我的图中看到了重叠,并不确定为什么会这样。
作为参考,我正在尝试对一个具有三个变量(Recency,Frequency,Revenue)的多维数据集进行聚类。为了可视化聚类,我可以使用PCA将3D数据投影到2D上,并在其上运行k-means。下面是我获得的代码和图:
df1=tx_user[["Recency","Frequency","Revenue"]]
#standardize
names = df1.columns
# Create the Scaler object
scaler = preprocessing.StandardScaler()
# Fit your data on the scaler object
scaled_df1 = scaler.fit_transform(df1)
df1 = pd.DataFrame(scaled_df1, columns=names)
df1.head()
del scaled_df1
sklearn_pca = PCA(n_components = 2)
X1 = sklearn_pca.fit_transform(df1)
X1 = X1[:, ::-1] # flip axes for better plotting
kmeans = KMeans(3, random_state=0)
labels = kmeans.fit(X1).predict(X1)
plt.scatter(X1[:, 0], X1[:, 1], c=labels, s=40, cmap='viridis');
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
def plot_kmeans(kmeans, X, n_clusters=4, rseed=0, ax=None):
labels = kmeans.fit_predict(X)
# plot the input data
ax = ax or plt.gca()
ax.axis('equal')
#ax.set_ylim(-5000,7000)
ax.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis', zorder=2)
# plot the representation of the KMeans model
centers = kmeans.cluster_centers_
radii = [cdist(X[labels == i], [center]).max()
for i, center in enumerate(centers)]
for c, r in zip(centers, radii):
ax.add_patch(plt.Circle(c, r, fc='#CCCCCC', lw=3, alpha=0.5, zorder=1))
kmeans = KMeans(n_clusters=4, random_state=0)
plot_kmeans(kmeans, X1)
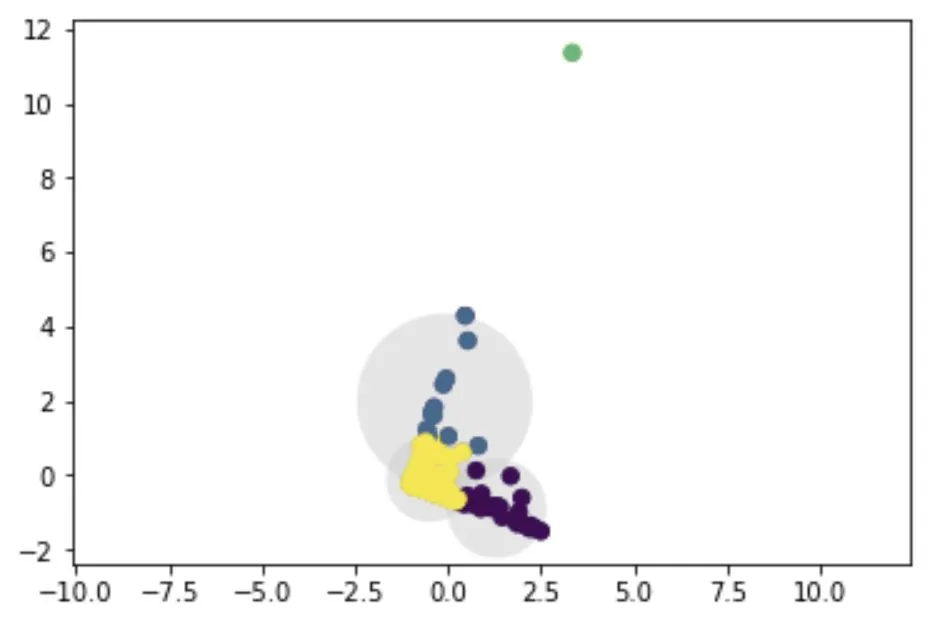
我的问题是: 1. 为什么会存在重叠区域?如果存在重叠区域,我的聚类是否就出现了错误? 2. 如果存在重叠区域,K均值聚类如何决定聚类分配?
谢谢
参考文献: Chen, L., Xu, Z., Wang, H., & Liu, S. (2018). An ordered clustering algorithm based on K-means and the PROMETHEE method. International Journal of Machine Learning and Cybernetics, 9(6), 917-926.