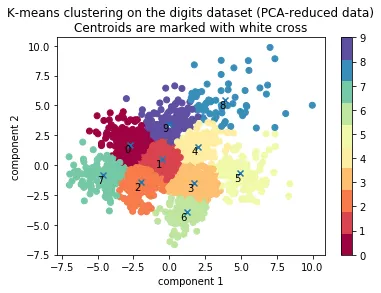
我正在使用Python对Mnist数据库(http://yann.lecun.com/exdb/mnist/)进行k-means聚类。我能够成功地对数据进行聚类,但无法为聚类打标签。也就是说,我无法看到哪个聚类编号持有哪个数字。例如,聚类5可以持有数字7。
在完成k-means聚类后,我需要编写代码来正确标记聚类,并向代码添加图例。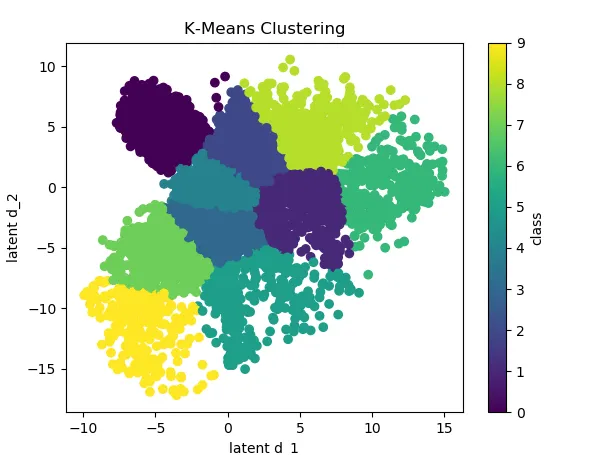
在完成k-means聚类后,我需要编写代码来正确标记聚类,并向代码添加图例。
from __future__ import division, print_function, absolute_import
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D #only needed for 3D plots
#scikit learn
from sklearn.cluster import KMeans
#pandas to read excel file
import pandas
import xlrd
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
Links:
[MNIST Dataset] http://yann.lecun.com/exdb/mnist/
df = pandas.read_csv('test_encoded_with_label.csv',header=None,
delim_whitespace=True)
#df = pandas.read_excel('test_encoded_with_label.xls')
#print column names
print(df.columns)
df1 = df.iloc[:,0:2] #0 and 1, the last index is not used for iloc
labels = df.iloc[:,2]
labels = labels.values
dataset = df1.values
#train indices - depends how many samples
trainidx = np.arange(0,9999)
testidx = np.arange(0,9999)
train_data = dataset[trainidx,:]
test_data = dataset[testidx,:]
train_labels = labels[trainidx] #just 1D, no :
tpredct_labels = labels[testidx]
kmeans = KMeans(n_clusters=10, random_state=0).fit(train_data)
kmeans.labels_
#print(kmeans.labels_.shape)
plt.scatter(train_data[:,0],train_data[:,1], c=kmeans.labels_)
predct_labels = kmeans.predict(train_data)
print(predct_labels)
print('actual label', tpredct_labels)
centers = kmeans.cluster_centers_
print(centers)
plt.show()