有没有人有使用不同字体进行OCR的经验?我生成一个ID,然后尝试用tesseract进行扫描。目前我只是尝试使用不同的字体,但这似乎相当低效。我已经尝试了OCR*字体系列和其他各种字体,如Arial和Georgia。tesseract往往会对OCR*字体感到困惑。
是否有专门为tesseract设计的字体,或者任何可与其良好配合的系统字体?
有没有人有使用不同字体进行OCR的经验?我生成一个ID,然后尝试用tesseract进行扫描。目前我只是尝试使用不同的字体,但这似乎相当低效。我已经尝试了OCR*字体系列和其他各种字体,如Arial和Georgia。tesseract往往会对OCR*字体感到困惑。
是否有专门为tesseract设计的字体,或者任何可与其良好配合的系统字体?
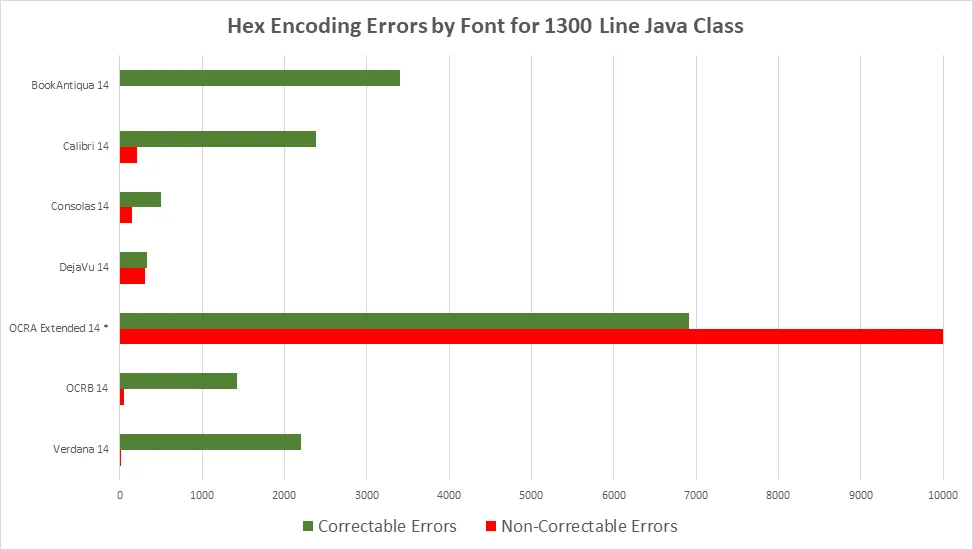
尝试了许多不同的字体和OCR引擎后,我发现使用Consolas可以获得最佳的结果。它是类似OCR-A的等宽字体,但更容易被人类阅读。Consolas包含在多个Microsoft产品中。
还有一种Inconsolata的开源字体,受到Consolas的影响。考虑到许可细节,Inconsolata是Consolas的良好替代品。
在我的测试中,Calibri字体中的数字和空格并不总是被正确识别。OCR-A会出现很多阅读错误。我没有尝试MIRC,因为大多数人很难阅读。
注意:tesseract在可靠之前需要大量的测试和微调。在我们的情况下,我们转换到了商业许可的OCR引擎(ABBYY),特别是由于可靠性非常重要,而且我们需要支持多种(欧洲)语言。
更新:2017年1月31日 - 由于潜在的版权问题,将“基于Consolas”更改为“受到Consolas的影响”。
我发现Calibri对我来说效果最好。我们每天在自动化系统中使用OCR软件,并测试了许多字体(包括一些OCR特定的字体),发现Calibri始终表现最佳。
祝你好运。
这实际上取决于所考虑的OCR引擎。
对于gocr,FreeMono是最好的选择,请参见gocr文档。
对于tesseract,DejaVu-Serif效果良好,请参见https://superuser.com/a/1543382/280936
对于abbyocr,verdana不错,请参见此比较
还可以参考这篇总结:https://www.monperrus.net/martin/perfect-ocr-digital-data
我一直都是用 times new roman 字体取得成功的。
奇怪的是,其他人使用Calibri取得了成功。在我的测试中,它的表现非常糟糕,经常将看起来相似的字母和数字混淆。最好的字体(在安装了Office的Windows计算机上)是Consolas、Verdana和Book Antiqua。所有这些都是动态衬线字体,字母和数字看起来很清晰。Consolas是冠军。
目前使用的是等宽字体。尝试了很多字体,但这对我来说是最准确的。