我正在使用编译好的.NET版本OCR,可以在http://www.pixel-technology.com/freeware/tessnet2/找到。
我已经让它工作了,但是这个OCR的目的是翻译车牌号码,不幸的是,引擎不能准确地翻译一些字母,例如,这里有一张图片,我扫描出了字符问题:

结果如下:
12345B7B9U ABCDEFGHIJKLMNUPIJRSTUVHXYZ
因此以下字符被错误地翻译:
1、O、Q、W
这看起来不太严重,但是对于我的车牌号码来说,结果并不理想:
 = H4 ODM
= H4 ODM
 = LDH IFW
= LDH IFW
虚假测试
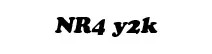 = NR4 y2k
= NR4 y2k
你可能已经注意到了,我尝试了降噪、增加对比度和去除不是绝对黑色的像素,但没有什么实质性的改善。
显然,你可以“教”引擎新字体,但我认为我需要重新编译.NET库,而且这似乎是在Linux操作系统上执行的,我没有这个系统。
http://www.scribd.com/doc/16747664/Tesseract-Trainingfor-Khmer-LanguageFor-Posting
所以我不知道下一步该怎么办,我写了一个快速测试控制台应用程序,如果有人想尝试它,请随便试试。 如果有任何想法/图形操作/库想法,我很乐意听到它们。