我将尝试使用Tesseract-OCR来检测图像中的纯文本,但这些文本具有一种名为Journal的手写字体。
示例:
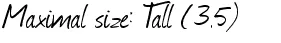
结果不是最好的:
最大值!尺寸为 W(35)
是否有任何可能改善结果或获得精确结果?
示例:
结果不是最好的:
最大值!尺寸为 W(35)
是否有任何可能改善结果或获得精确结果?
正如Andrew Cash所提到的那样,由于它与许多下一个字符的交叉,对于那个T字母执行OCR将非常困难。
为了改善结果,您可能需要尝试更准确的SDK。看看ABBYY Cloud OCR SDK,这是ABBYY最近推出的基于云的OCR SDK。它目前处于测试阶段,因此现在完全免费使用。我在ABBYY工作,如果需要,可以为您提供有关我们产品的其他信息。我已经将您附加的图像发送到我们的SDK,并获得了以下响应:
Maximal size: lall (35)