我知道你正在寻找开源的解决方案,但我想与你分享一下,使用 Adobe API 可以实现这一点;你可以从这里免费试用:
Adobe API Developer。
以下是 Python 函数(确保从 Adobe API 中获取 'private.Key'(
https://developer.adobe.com/document-services/docs/overview/pdf-extract-api/)。点击开始试用后,你将在下载到你的计算机上的压缩文件中找到该文件。
from adobe.pdfservices.operation.auth.credentials import Credentials
from adobe.pdfservices.operation.exception.exceptions import ServiceApiException, ServiceUsageException, SdkException
from adobe.pdfservices.operation.pdfops.options.extractpdf.extract_pdf_options import ExtractPDFOptions
from adobe.pdfservices.operation.pdfops.options.extractpdf.extract_renditions_element_type import \
ExtractRenditionsElementType
from adobe.pdfservices.operation.pdfops.options.extractpdf.extract_element_type import ExtractElementType
from adobe.pdfservices.operation.execution_context import ExecutionContext
from adobe.pdfservices.operation.io.file_ref import FileRef
from adobe.pdfservices.operation.pdfops.extract_pdf_operation import ExtractPDFOperation
import logging
import os
import re
import zipfile
import json
import glob
import pandas as pd
def adobeAPI(base_path, file_path):
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
try:
credentials = Credentials.service_account_credentials_builder() \
.from_file("/path/to/pdfservices-api-credentials.json") \
.build()
execution_context = ExecutionContext.create(credentials)
extract_pdf_operation = ExtractPDFOperation.create_new()
source = FileRef.create_from_local_file(file_path)
extract_pdf_operation.set_input(source)
extract_pdf_options: ExtractPDFOptions = ExtractPDFOptions.builder() \
.with_elements_to_extract([ExtractElementType.TEXT, ExtractElementType.TABLES]) \
.with_elements_to_extract_renditions([ExtractRenditionsElementType.TABLES,
ExtractRenditionsElementType.FIGURES]) \
.build()
extract_pdf_operation.set_options(extract_pdf_options)
result: FileRef = extract_pdf_operation.execute(execution_context)
outputzip = os.path.join(base_path, "output", str(
get_filename(file_path)+".zip"))
outputzipextract = os.path.join(
base_path, "output", str(get_filename(file_path)))
result.save_as(outputzip)
except (ServiceApiException, ServiceUsageException, SdkException):
logging.exception("Exception encountered while executing operation")
with zipfile.ZipFile(outputzip, 'r') as zip_ref:
zip_ref.extractall(path=outputzipextract)
with open(os.path.join(outputzipextract, "structuredData.json")) as json_file:
data = json.load(json_file)
List_xlsx_files = []
xlsx_files = glob.glob(os.path.join(
outputzipextract, "tables", "*.xlsx"))
for file in xlsx_files:
List_xlsx_files.append(file)
list_of_values = list(range(len(data['elements'])-1))
filename = get_filename(file_path)
with open(os.path.join(outputzipextract, str(filename + '.txt')), "w", encoding='utf-8') as file:
concatenated_string = ""
for sec_index in list_of_values:
pattern_figure = r"Figure$"
match_figure = re.search(
pattern_figure, data['elements'][int(sec_index)]['Path'])
pattern_table_all = r"\/Table(?:\[\d+\])?$"
match_table_all = re.search(
pattern_table_all, data['elements'][int(sec_index)]['Path'])
pattern_table_part = r"/Table(?:\[\d+\])?/"
match_table_part = re.search(
pattern_table_part, data['elements'][int(sec_index)]['Path'])
if match_figure or match_table_part:
continue
elif match_table_all:
xlsx_file = List_xlsx_files[0]
match = re.search(r'(?<=\\)[^\\]*$', xlsx_file)
xlsx_file = match.group(0)
dfs_fixed_dict = get_dict_xlsx(outputzipextract, xlsx_file)
json_string = json.dumps(dfs_fixed_dict)
concatenated_string = concatenated_string + "\n" + json_string
List_xlsx_files.pop(0)
elif 'Text' in data['elements'][int(sec_index)]:
concatenated_string = concatenated_string + \
"\n" + data['elements'][int(sec_index)]['Text']
else:
continue
file.write(concatenated_string)
localfile = os.path.join(outputzipextract, str(filename + '.txt'))
return localfile
def get_filename(file_path):
pattern = r'[/\\]([^/\\]+)\.pdf$'
match = re.search(pattern, file_path)
if match:
return match.group(1)
else:
return None
def get_dict_xlsx(outputzipextract, xlsx_file):
dfs = pd.read_excel(os.path.join(
outputzipextract, "tables", xlsx_file), sheet_name='Sheet1', engine='openpyxl')
data_dict = dfs.to_dict(orient='records')
cleaned_data_dict = [
{re.sub(r'_x[0-9a-fA-F]{4}_', '', k).strip()
: re.sub(r'_x[0-9a-fA-F]{4}_', '', v).strip() for k, v in item.items()}
for item in data_dict
]
return cleaned_data_dict
这是运行代码之前的文件结构:
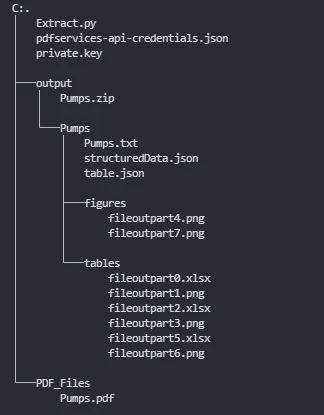
运行后,您将拥有一个名为“output”的文件夹,在其中可以找到您的PDF的txt版本。当您打开txt文件时,您会注意到其中的表格以json格式呈现。GPT能够读取json并在尝试回答您的问题时加以考虑。
在我的PDF文件中,有一个表格:
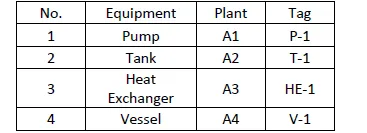
您的txt文件包含了这个的JSON格式。
[{
"No.": "1",
"Equipment": "Pump",
"Plant": "A1",
"Tag": "P-1"
}, {
"No.": "2",
"Equipment": "Tank",
"Plant": "A2",
"Tag": "T-1"
}, {
"No.": "3",
"Equipment": "Heat Exchanger",
"Plant": "A3",
"Tag": "HE-1"
}, {
"No.": "4",
"Equipment": "Vessel",
"Plant": "A4",
"Tag": "V-1"
}]
运行代码后,这是文件结构:
希望能有所帮助。