我有这个简单的数据框(data.frame)
lat<-c(1,2,3,10,11,12,20,21,22,23)
lon<-c(5,6,7,30,31,32,50,51,52,53)
data=data.frame(lat,lon)
该想法是基于距离找到空间聚类。
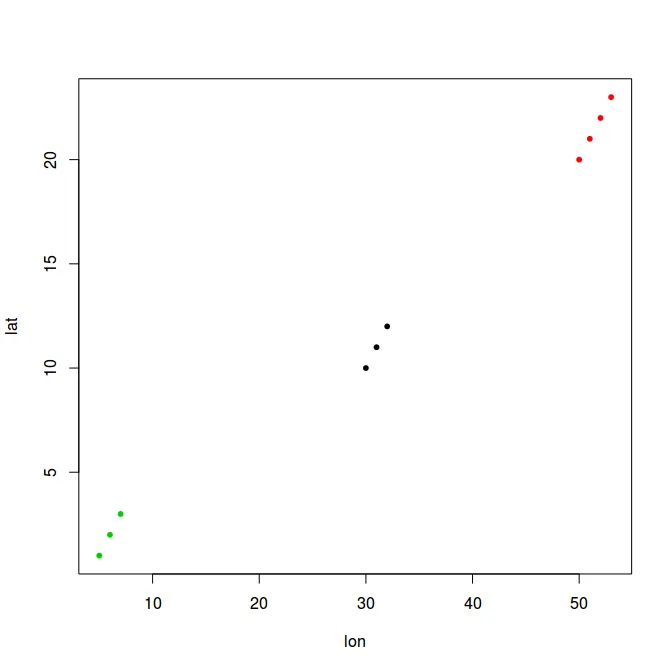
首先,我绘制地图(经度,纬度):
plot(data$lon,data$lat)
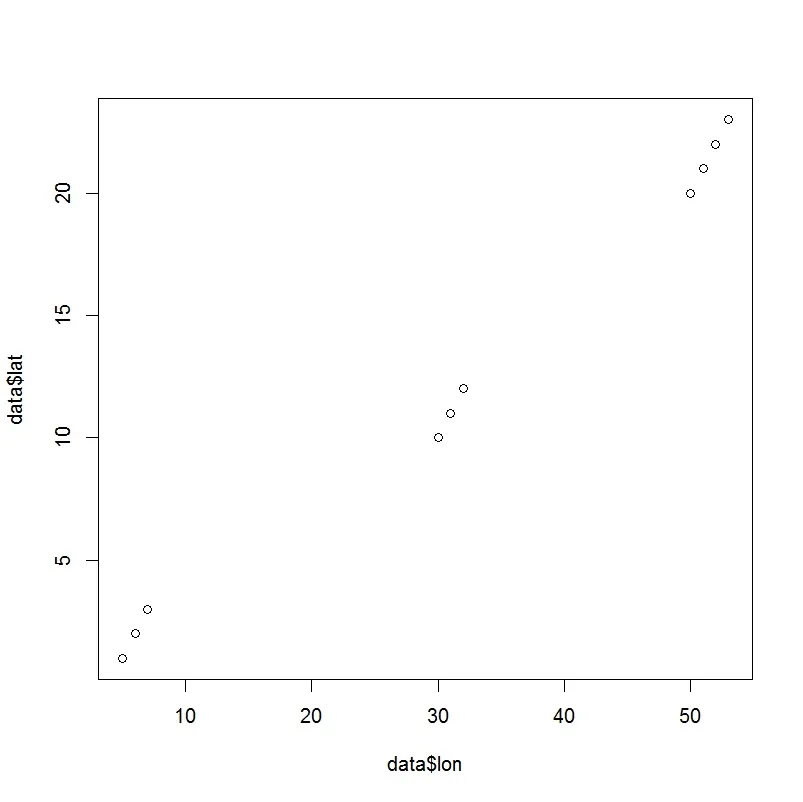
因此,根据点的位置之间的距离,我明显有三个聚类。
为了达到这个目的,我在R中尝试了以下代码:
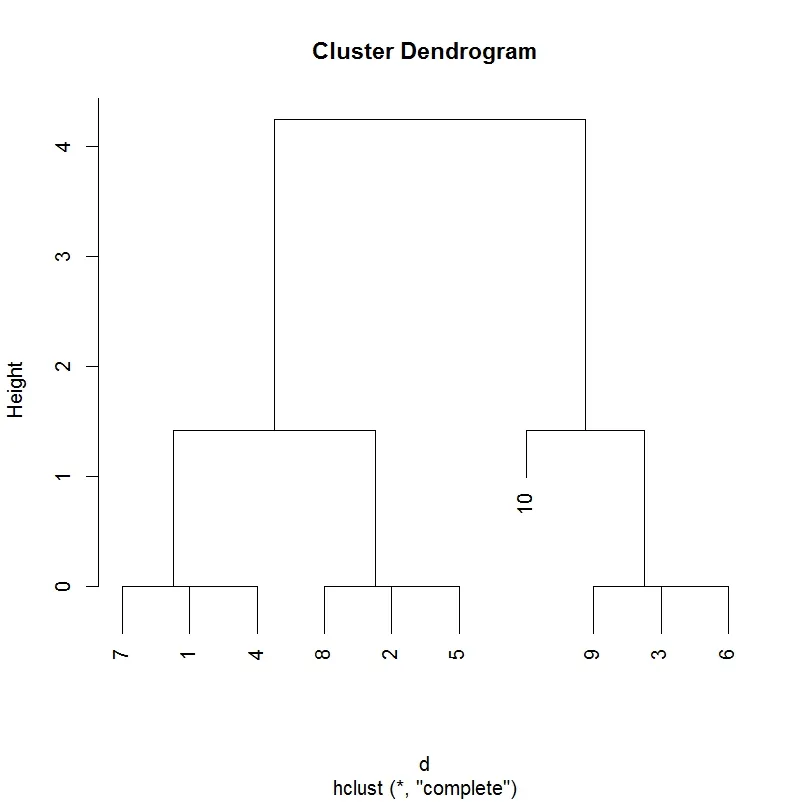
d= as.matrix(dist(cbind(data$lon,data$lat))) #Creat distance matrix
d=ifelse(d<5,d,0) #keep only distance < 5
d=as.dist(d)
hc<-hclust(d) # hierarchical clustering
plot(hc)
data$clust <- cutree(hc,k=3) # cut the dendrogram to generate 3 clusters
这给出了:
现在我尝试绘制相同的点,但使用聚类的颜色。
plot(data$x,data$y, col=c("red","blue","green")[data$clust],pch=19)
这是结果:
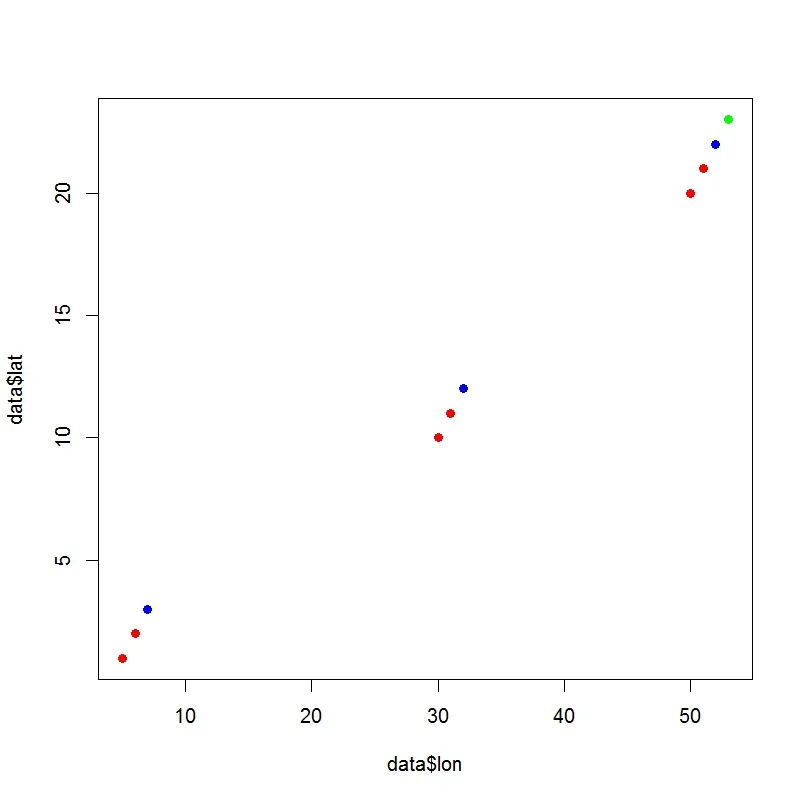
但这不是我要找的。
事实上,我想要找类似于这张图的绘图:
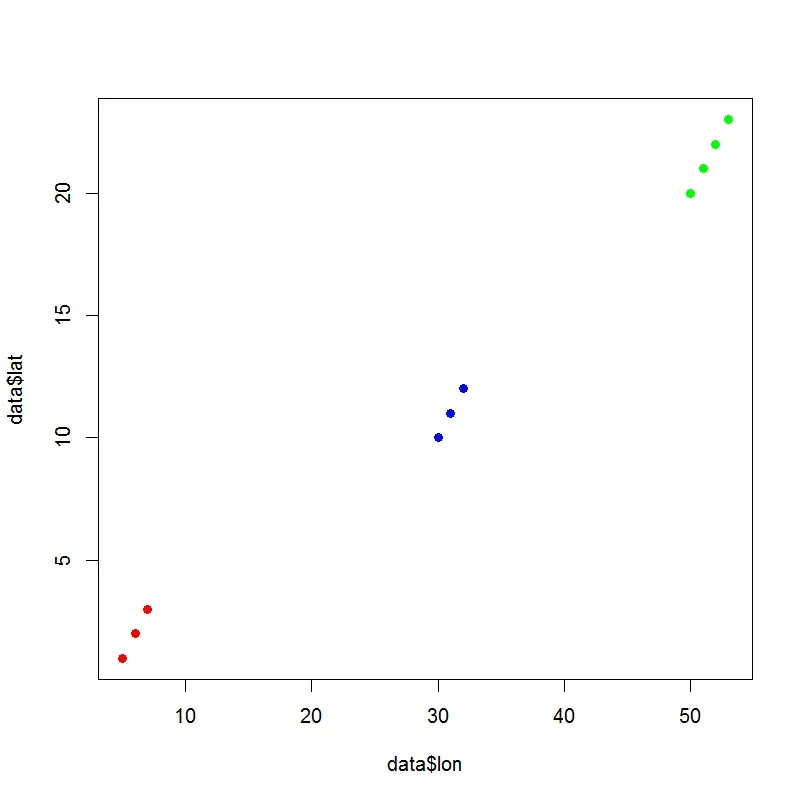
感谢您的帮助。

hc <- hclust(dist(data)); clust <- cutree(hc, 3),它将按预期工作。 - nico