假设我有一个单词计数的示例,其中我在一列中获取一个数据框作为单词,另一列中获取单词计数,我想将其收集并存储为JSON数组以在Mongo集合中使用。
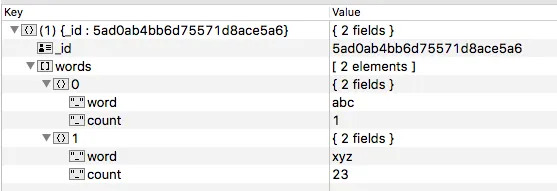
我应该得到以下类似的JSON格式数据:
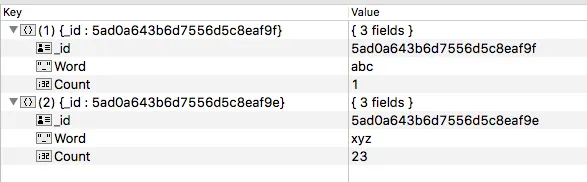
当我在数据框上尝试使用 .toJSON 方法并将值收集为列表,然后将其添加到数据框中时,结果存储在我的 MongoDB 中的是一组字符串而不是一组 JSON。
查询语句使用如下:
eg for dataframe:
|Word | Count |
| abc | 1 |
| xyz | 23 |
我应该得到以下类似的JSON格式数据:
{words:[{word:"abc",count:1},{word:"xyz",count:23}]}
当我在数据框上尝试使用 .toJSON 方法并将值收集为列表,然后将其添加到数据框中时,结果存储在我的 MongoDB 中的是一组字符串而不是一组 JSON。
查询语句使用如下:
explodedWords1.toJSON.toDF("words").agg(collect_list("words")).toDF("words")
result : "{\"words\":[{\"word\":\"abc\",\"count\":1},{\"word\":\"xyz\",\"count\":23}]}"
我是Scala的新手。任何帮助都会很好。(如果不使用外部包会更好)。
.groupBy('userid)。 - Tom Lous