池化和卷积操作在输入张量上滑动一个“窗口”。以tf.nn.conv2d为例:如果输入张量有四个维度:[batch, height, width, channels],那么卷积在height, width维度上的二维窗口上运算。
strides决定了窗口在每个维度上移动的距离。一般用法将第一个(批次)和最后一个(深度)步长设置为1。
我们来看一个非常具体的例子:对一个 32x32 的灰度输入图像进行 2D 卷积运算。这里使用灰度图是因为它的深度等于 1,这使得问题简单化。假设该图像长这样:
00 01 02 03 04 ...
10 11 12 13 14 ...
20 21 22 23 24 ...
30 31 32 33 34 ...
...
让我们在单个示例上运行一个2x2的卷积窗口(批量大小=1)。我们将给卷积一个8的输出通道深度。
卷积的输入具有shape=[1, 32, 32, 1]。
如果您使用strides=[1,1,1,1]和padding=SAME指定,则滤波器的输出将为[1, 32, 32, 8]。
滤波器将首先为以下内容创建输出:
F(00 01
10 11)
然后是:
F(01 02
11 12)
等等。然后它将移动到第二行,计算:
F(10, 11
20, 21)
然后
F(11, 12
21, 22)
F(00, 01
10, 11)
然后
F(02, 03
12, 13)
对于池化操作,步幅的操作方式类似。
问题2:为什么卷积神经网络使用步幅 [1,x,y,1]?
第一个1表示批处理大小:通常不希望跳过批处理中的示例,否则就不应该在第一次包含它们。 :)
最后一个1是卷积的深度:出于相同的原因,通常不希望跳过输入。
Conv2d运算符更加通用,因此您可以创建沿其他维度滑动窗口的卷积,但这不是卷积神经网络的典型用途。 典型用途是在空间上使用它们。
为什么要重塑成-1 -1是一个占位符,表示“根据需要调整以匹配完整张量所需的大小”。 这是使代码独立于输入批处理大小的一种方法,因此可以更改管道而不必在代码的各个位置调整批处理大小。
1
输入数据是四维的,其形式为:[batch_size, image_rows, image_cols, number_of_colors]
步幅通常用于定义操作之间的重叠。在conv2d的情况下,它指定了卷积过滤器连续应用之间的距离。特定维度上的值1表示我们在每一行/列上都应用操作符,值2表示每隔两行/列应用一次操作符,以此类推。
关于问题1:卷积中重要的值是第二个和第三个,它们代表卷积过滤器沿行和列的应用重叠。 [1, 2, 2, 1] 的值表示我们希望在每隔两行和两列上应用过滤器。
关于问题2:我不知道技术限制(可能是CuDNN的要求),但通常人们会在行或列维度上使用步幅。在批量大小上这样做可能没有意义。最后一个维度我不确定。
关于问题3:在某个维度上设置-1的意思是“设置第一个维度的值,使得张量中元素的总数不变”。在我们的情况下,-1将等于batch_size。
让我们先来看一维情况下stride的作用。
假设您的 input = [1, 0, 2, 3, 0, 1, 1],kernel = [2, 1, 3] ,卷积的结果是[8, 11, 7, 9, 4]。在计算中,滑动您的卷积核(kernel)在输入(input)上,执行逐元素乘法并将所有结果相加。就像这样:
- 8 = 1 * 2 + 0 * 1 + 2 * 3
- 11 = 0 * 2 + 2 * 1 + 3 * 3
- 7 = 2 * 2 + 3 * 1 + 0 * 3
- 9 = 3 * 2 + 0 * 1 + 1 * 3
- 4 = 0 * 2 + 1 * 1 + 1 * 3
我们在这里每次滑动一个元素,但用任何其他数字也可以。 这个数字就是步幅(stride)。 您可以将其视为通过仅取每s个结果来对1步幅(strided)卷积的结果进行下采样。
如果知道输入大小i、卷积核大小k、步幅(stride)s和填充(padding)p,则可以轻松计算卷积的输出大小如下:
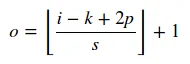
这里的 || 运算符表示向上取整操作。 对于池化层s = 1。
N维情况
了解了一维情况下的数学知识,理解多维情况就容易了,因为每个维度是相互独立的。所以你只需要分别滑动每个维度。这里有一个二维的例子。注意,你不需要在所有维度上都使用相同的步长。因此,对于N维输入/核心,应提供N个步长。
现在回答您的所有问题变得容易了:
- 4个及以上的整数代表什么? conv2d,pool 告诉您,此列表表示每个维度之间的步幅。请注意,步幅列表的长度与内核张量的秩相同。
- 为什么必须让 strides[0] = strides3 = 1 用于卷积神经网络? 第一个维度是批次大小,最后一个是通道数。跳过批次和通道没有意义。因此使它们为1。对于宽度/高度,您可以跳过一些内容,这就是它们可能不是1的原因。
- tf.reshape(_X, shape=[-1, 28, 28, 1])。为什么是 -1? tf.reshape 已经为您处理好了:
如果shape的某个组件是特殊值-1,则计算该维度的大小,以便总大小保持不变。特别地,shape为[-1]展平为1-D。shape中最多只有一个分量可以是-1。
stride在3D卷积中是如何工作的。根据TensorFlow文档上对conv3d的说明,输入的形状必须按照以下顺序排列:
[batch, in_depth, in_height, in_width, in_channels]
让我们使用一个例子,从极右边到左边解释变量。假设输入形状为input_shape = [1000,16,112,112,3]。input_shape[4] is the number of colour channels (RGB or whichever format it is extracted in)
input_shape[3] is the width of the image
input_shape[2] is the height of the image
input_shape[1] is the number of frames that have been lumped into 1 complete data
input_shape[0] is the number of lumped frames of images we have.
以下是关于步幅如何使用的摘要文档。
步幅(strides):一个长度大于等于5的整数列表,长度为5的1维张量。每个输入维度的滑动窗口的步幅。必须满足
strides[0] = strides[4] = 1。正如许多作品所指出的那样,步幅简单地表示窗口或卷积核距离最近元素(数据帧或像素)跳跃的步数(这是引用的意思)。
从上述文档中可以看出,3D中的步幅将如下所示:strides = (1, X, Y, Z, 1)。
文档强调了
strides[0] = strides[4] = 1。strides[0]=1 means that we do not want to skip any data in the batch
strides[4]=1 means that we do not want to skip in the channel
strides[X] 表示在合并的帧中应该跳过多少步。例如,如果有16个帧,则X=1表示使用每个帧。X=2表示每隔一个帧使用一次,以此类推。
strides[y] 和 strides[z] 遵循 @dga 的解释,因此我不会重复解释。
在 keras 中,您只需要指定一个包含3个整数的元组/列表,指定卷积沿每个空间维度的步幅,其中空间维度是 stride[x]、stride[y] 和 stride[z]。strides[0] 和 strides[4] 已经默认为 1。
希望对某些人有所帮助!
原文链接