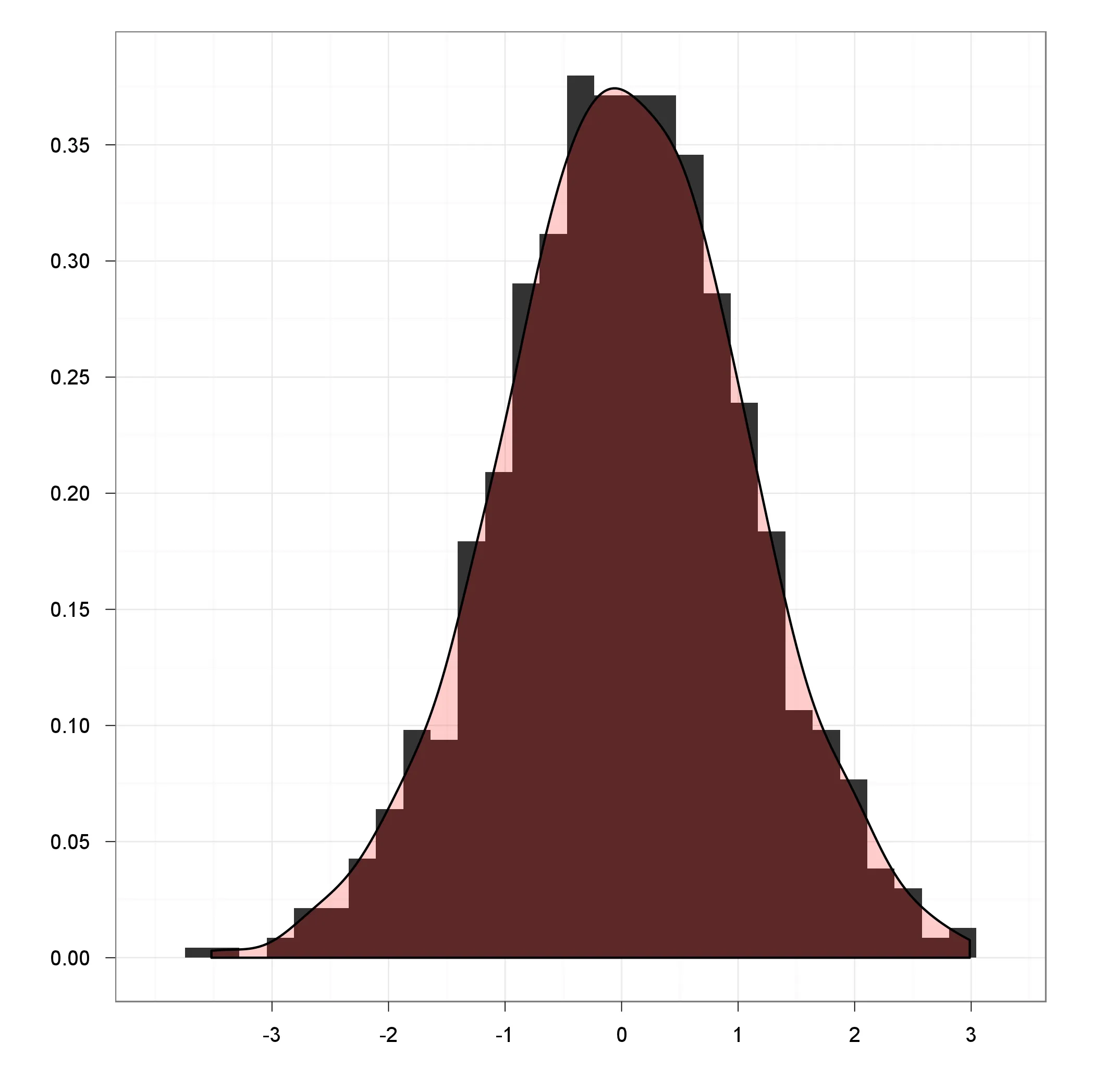
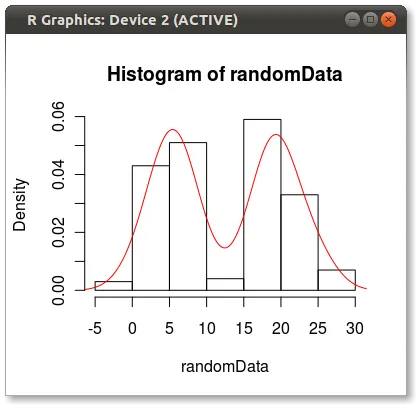
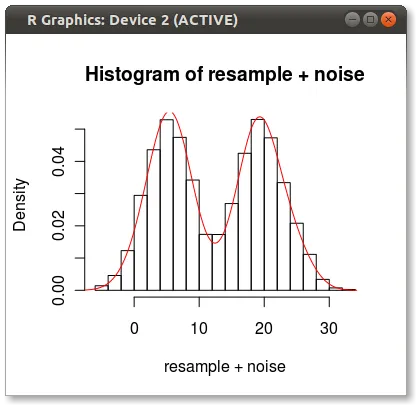
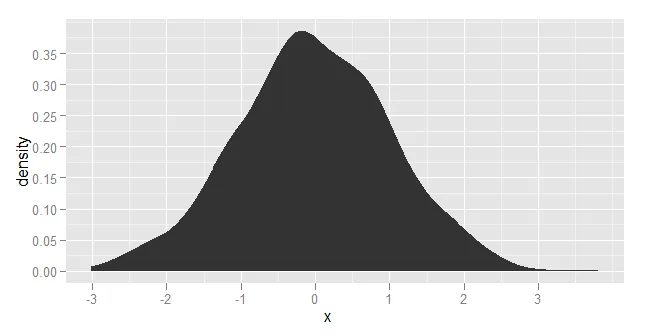
我希望绘制数据,使y轴上的值为概率(在[0,1]范围内),x轴上的值为数据值。数据是连续的(也在[0,1]范围内),因此我想使用一些核密度估计函数并对其进行归一化,使得某个点x处的y值表示在输入数据中看到值x的概率。
所以,我想问:
a)这样合理吗?我知道我不能有看不到的值的概率,但我只是想使用核密度估计函数在我有的点之间进行插值,并在归一化后使用它。
b)ggplot中是否有任何内置选项可以用于覆盖geom_density()的默认行为,例如执行此操作?
提前感谢,
Timo
编辑:当我之前说“归一化”时,实际上我是指“缩放”。但我已经得到了答案,所以感谢大家帮我澄清这一点。
所以,我想问:
a)这样合理吗?我知道我不能有看不到的值的概率,但我只是想使用核密度估计函数在我有的点之间进行插值,并在归一化后使用它。
b)ggplot中是否有任何内置选项可以用于覆盖geom_density()的默认行为,例如执行此操作?
提前感谢,
Timo
编辑:当我之前说“归一化”时,实际上我是指“缩放”。但我已经得到了答案,所以感谢大家帮我澄清这一点。