我认为一个小的代码示例比理论讨论更好地解释了问题。
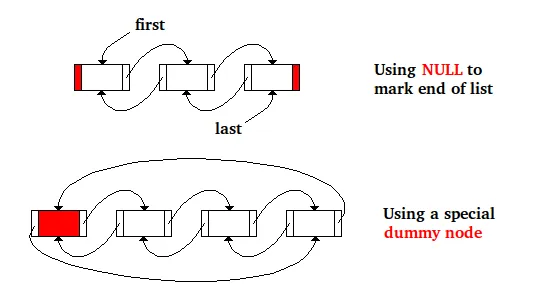
以下是删除双向链表节点的代码,其中使用NULL来标记列表的结尾,并使用两个指针first和last来保存第一个和最后一个节点的地址:
// Using NULL and pointers for first and last
if (n->prev) n->prev->next = n->next;
else first = n->next;
if (n->next) n->next->prev = n->prev;
else last = n->prev;
这段代码相同,只是使用了一个特殊的虚拟节点标记列表结尾,并且该列表中第一个节点的地址存储在特殊节点的next字段中,而最后一个节点存储在特殊虚拟节点的prev字段中:
// Using the dummy node
n->prev->next = n->next;
n->next->prev = n->prev;
对于节点插入,也存在相同类型的简化;例如,要在节点x之前插入节点n(当x == NULL或x == &dummy时表示插入到最后位置),代码应该是:
```c++
if (x == NULL) { // Insertion at the end
prev = tail;
} else {
prev = x->prev;
}
n->next = x;
n->prev = prev;
x->prev = n;
prev->next = n;
```
// Using NULL and pointers for first and last
n->next = x;
n->prev = x ? x->prev : last;
if (n->prev) n->prev->next = n;
else first = n;
if (n->next) n->next->prev = n;
else last = n;
并且
// Using the dummy node
n->next = x;
n->prev = x->prev;
n->next->prev = n;
n->prev->next = n;
如您所见,虚拟节点方法为双向链表消除了所有特殊情况和条件判断。
下面的图片表示了同一列表在内存中两种方法的不同实现...