在一个Excel文件中,第1个工作表上有4个不同位置的表格。如何读取这4个表格。例如,我甚至添加了一张来自谷歌的图片供参考。除了使用索引之外,还有其他方法可以提取这些表格吗?
然后有一个来自Samuel Oranyeli的很好的指南,教你如何用Python导入Excel表格。我已经使用了他的代码并进行了示范。
关于代码的说明:
以下部分可用于检查我们正在使用的工作表中存在哪些表:
# check what tables that exist in the worksheet
print({key : value for key, value in ws.tables.items()})
# Extract all the tables to individually dataframes from the dictionary
Table2, Table3, Table4, Table5 = mapping.values()
# Print each dataframe
print(Table2.head(3)) # Print first 3 rows from df
print(Table2.head(3)) 给出的结果是:
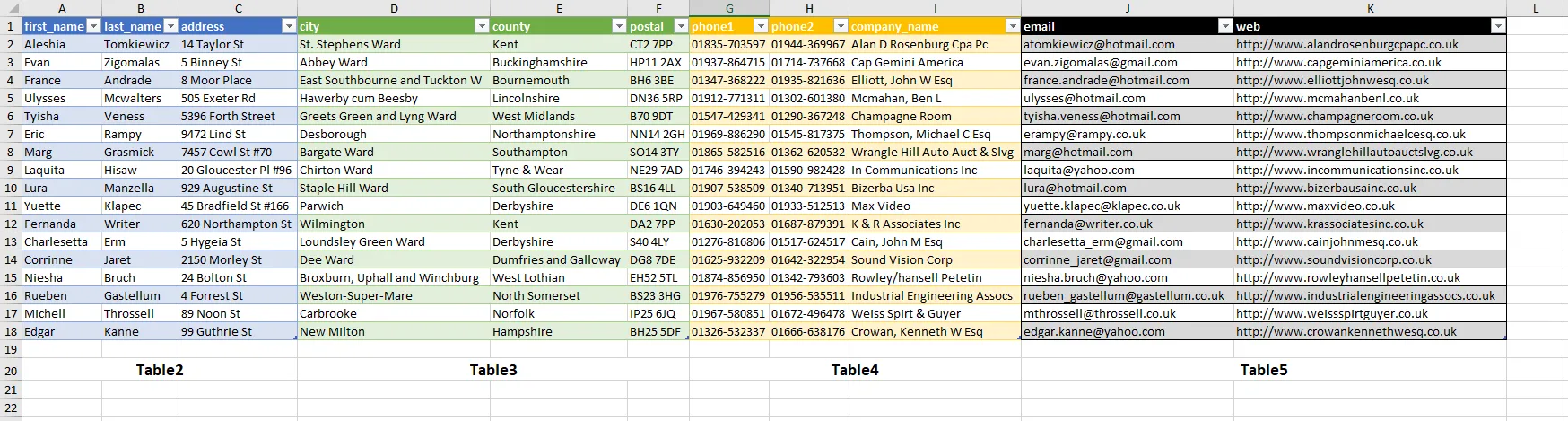
完整代码:Index first_name last_name address 0 Aleshia Tomkiewicz 14 Taylor St 1 Evan Zigomalas 5 Binney St 2 France Andrade 8 Moor Place
#import libraries
from openpyxl import load_workbook
import pandas as pd
# read file
wb = load_workbook("G:/Till/Tables.xlsx") # Set the filepath + filename
# select the sheet where tables are located
ws = wb["Tables"]
# check what tables that exist in the worksheet
print({key : value for key, value in ws.tables.items()})
mapping = {}
# loop through all the tables and add to a dictionary
for entry, data_boundary in ws.tables.items():
# parse the data within the ref boundary
data = ws[data_boundary]
### extract the data ###
# the inner list comprehension gets the values for each cell in the table
content = [[cell.value for cell in ent]
for ent in data]
header = content[0]
#the contents ... excluding the header
rest = content[1:]
#create dataframe with the column names
#and pair table name with dataframe
df = pd.DataFrame(rest, columns = header)
mapping[entry] = df
# print(mapping)
# Extract all the tables to individually dataframes from the dictionary
Table2, Table3, Table4, Table5 = mapping.values()
# Print each dataframe
print(Table2)
print(Table3)
print(Table4)
print(Table5)
示例数据,示例文件:
| 名字 | 姓氏 | 地址 | 城市 | 县区 | 邮政编码 |
|---|---|---|---|---|---|
| Aleshia | Tomkiewicz | 14 Taylor St | St. Stephens Ward | Kent | CT2 7PP |
| Evan | Zigomalas | 5 Binney St | Abbey Ward | Buckinghamshire | HP11 2AX |
| France | Andrade | 8 Moor Place | East Southbourne and Tuckton W | Bournemouth | BH6 3BE |
| Ulysses | Mcwalters | 505 Exeter Rd | Hawerby cum Beesby | Lincolnshire | DN36 5RP |
| Tyisha | Veness | 5396 Forth Street | Greets Green and Lyng Ward | West Midlands | B70 9DT |
| Eric | Rampy | 9472 Lind St | Desborough | Northamptonshire | NN14 2GH |
| Marg | Grasmick | 7457 Cowl St #70 | Bargate Ward | Southampton | SO14 3TY |
| Laquita | Hisaw | 20 Gloucester Pl #96 | Chirton Ward | Tyne & Wear | NE29 7AD |
| Lura | Manzella | 929 Augustine St | Staple Hill Ward | South Gloucestershire | BS16 4LL |
| Yuette | Klapec | 45 Bradfield St #166 | Parwich | Derbyshire | DE6 1QN |
| Fernanda | Writer | 620 Northampton St | Wilmington | Kent | DA2 7PP |
| Charlesetta | Erm | 5 Hygeia St | Loundsley Green Ward | Derbyshire | S40 4LY |
| Corrinne | Jaret | 2150 Morley St | Dee Ward | Dumfries and Galloway | DG8 7DE |
| Niesha | Bruch | 24 Bolton St | Broxburn, Uphall and Winchburg | West Lothian | EH52 5TL |
| Rueben | Gastellum | 4 Forrest St | Weston-Super-Mare | North Somerset | BS23 3HG |
| Michell | Throssell | 89 Noon St | Carbrooke | Norfolk | IP25 6JQ |
| Edgar | Kanne</ |
DefinedName查找文件中的表格:https://learn.microsoft.com/en-us/dotnet/api/documentformat.openxml.spreadsheet.definedname?view=openxml-2.8.1您可以将Excel表格转换为CSV文件,然后使用CSV模块来获取行。
//Excel转CSV的代码
import pandas as pd
read_file = pd.read_excel ("Test.xlsx")
read_file.to_csv ("Test.csv",index = None,header=True)
df = pd.DataFrame(pd.read_csv("Test.csv"))
print(df)
为了更好的方法,请提供样本Excel文件。
import pandas as pd
read_file = pd.read_excel("Test.xlsx")
read_file.to_csv ("Test.csv",index = None,header=True)
enter code here
df = pd.DataFrame(pd.read_csv("Test.csv"))
print(df)
为了更好的处理,请提供给我们一个样本Excel文件
- 你为什么不想使用索引?
- 你能描述表格位置、大小等约束条件吗?
- 你可以提供一个例子吗?
- mozway