我理解的是,您可以尝试使用窗口函数 collect_list,对列表进行排序,使用 array_position 找到当前行的位置 idx (需要 Spark 2.4+ 版本),然后基于此计算权重。让我们以窗口大小为7(或下面代码中的 N=3)为例:
from pyspark.sql.functions import expr, sort_array, collect_list, struct
from pyspark.sql import Window
df = spark.createDataFrame([
(0, 0.5), (1, 0.6), (2, 0.65), (3, 0.7), (4, 0.77),
(5, 0.8), (6, 0.7), (7, 0.9), (8, 0.99), (9, 0.95)
], ["time", "val"])
N = 3
w1 = Window.partitionBy().orderBy('time').rowsBetween(-N,N)
df1 = df.withColumn('data', sort_array(collect_list(struct('time','val')).over(w1))) \
.withColumn('idx', expr("array_position(data, (time,val))-1")) \
.withColumn('weights', expr("transform(data, (x,i) -> 10 - abs(i-idx))"))
df1.show(truncate=False)
+----+----+-------------------------------------------------------------------------+---+----------------------+
|time|val |data |idx|weights |
+----+----+-------------------------------------------------------------------------+---+----------------------+
|0 |0.5 |[[0, 0.5], [1, 0.6], [2, 0.65], [3, 0.7]] |0 |[10, 9, 8, 7] |
|1 |0.6 |[[0, 0.5], [1, 0.6], [2, 0.65], [3, 0.7], [4, 0.77]] |1 |[9, 10, 9, 8, 7] |
|2 |0.65|[[0, 0.5], [1, 0.6], [2, 0.65], [3, 0.7], [4, 0.77], [5, 0.8]] |2 |[8, 9, 10, 9, 8, 7] |
|3 |0.7 |[[0, 0.5], [1, 0.6], [2, 0.65], [3, 0.7], [4, 0.77], [5, 0.8], [6, 0.7]] |3 |[7, 8, 9, 10, 9, 8, 7]|
|4 |0.77|[[1, 0.6], [2, 0.65], [3, 0.7], [4, 0.77], [5, 0.8], [6, 0.7], [7, 0.9]] |3 |[7, 8, 9, 10, 9, 8, 7]|
|5 |0.8 |[[2, 0.65], [3, 0.7], [4, 0.77], [5, 0.8], [6, 0.7], [7, 0.9], [8, 0.99]]|3 |[7, 8, 9, 10, 9, 8, 7]|
|6 |0.7 |[[3, 0.7], [4, 0.77], [5, 0.8], [6, 0.7], [7, 0.9], [8, 0.99], [9, 0.95]]|3 |[7, 8, 9, 10, 9, 8, 7]|
|7 |0.9 |[[4, 0.77], [5, 0.8], [6, 0.7], [7, 0.9], [8, 0.99], [9, 0.95]] |3 |[7, 8, 9, 10, 9, 8] |
|8 |0.99|[[5, 0.8], [6, 0.7], [7, 0.9], [8, 0.99], [9, 0.95]] |3 |[7, 8, 9, 10, 9] |
|9 |0.95|[[6, 0.7], [7, 0.9], [8, 0.99], [9, 0.95]] |3 |[7, 8, 9, 10] |
+----+----+-------------------------------------------------------------------------+---+----------------------+
接下来,我们可以使用SparkSQL内置函数aggregate来计算权重和加权值的总和:
N = 9
w1 = Window.partitionBy().orderBy('time').rowsBetween(-N,N)
df_new = df.withColumn('data', sort_array(collect_list(struct('time','val')).over(w1))) \
.withColumn('idx', expr("array_position(data, (time,val))-1")) \
.withColumn('weights', expr("transform(data, (x,i) -> 10 - abs(i-idx))"))\
.withColumn('sum_weights', expr("aggregate(weights, 0D, (acc,x) -> acc+x)")) \
.withColumn('weighted_val', expr("""
aggregate(
zip_with(data,weights, (x,y) -> x.val*y),
0D,
(acc,x) -> acc+x,
acc -> acc/sum_weights
)""")) \
.drop("data", "idx", "sum_weights", "weights")
df_new.show()
+----+----+------------------+
|time| val| weighted_val|
+----+----+------------------+
| 0| 0.5|0.6827272727272726|
| 1| 0.6|0.7001587301587302|
| 2|0.65|0.7169565217391304|
| 3| 0.7|0.7332876712328767|
| 4|0.77| 0.7492|
| 5| 0.8|0.7641333333333333|
| 6| 0.7|0.7784931506849315|
| 7| 0.9|0.7963768115942028|
| 8|0.99|0.8138095238095238|
| 9|0.95|0.8292727272727273|
+----+----+------------------+
注意事项:
you can calculate multiple columns by setting struct('time','val1', 'val2') in the first line of calculating df_new and then adjust the corresponding calculation of idx and x.val*y in weighted_val etc.
to set NULL when less than half values are not able to be collected, add a IF(size(data) <= 9, NULL, ...) or IF(sum_weights < 40, NULL, ...) statement to the following:
df_new = df.withColumn(...) \
...
.withColumn('weighted_val', expr(""" IF(size(data) <= 9, NULL,
aggregate(
zip_with(data,weights, (x,y) -> x.val*y),
0D,
(acc,x) -> acc+x,
acc -> acc/sum_weights
))""")) \
.drop("data", "idx", "sum_weights", "weights")
编辑:如果需要多列,可以尝试以下方法:
cols = ['val1', 'val2', 'val3']
weighted_vals = lambda val: """
aggregate(
zip_with(data,weights, (x,y) -> x.{0}*y),
0D,
(acc,x) -> acc+x,
acc -> acc/sum_weights
) as weighted_{0}
""".format(val)
df_new = df.withColumn('data', sort_array(collect_list(struct('time',*cols)).over(w1))) \
.withColumn('idx', expr("array_position(data, (time,{}))-1".format(','.join(cols)))) \
.withColumn('weights', expr("transform(data, (x,i) -> 10 - abs(i-idx))")) \
.withColumn('sum_weights', expr("aggregate(weights, 0D, (acc,x) -> acc+x)")) \
.selectExpr(df.columns + [ weighted_vals(c) for c in cols ])
如果列的数量有限,我们可以编写 SQL 表达式来使用一个聚合函数计算加权值:
df_new = df.withColumn('data', sort_array(collect_list(struct('time',*cols)).over(w1))) \
.withColumn('idx', expr("array_position(data, (time,{}))-1".format(','.join(cols)))) \
.withColumn('weights', expr("transform(data, (x,i) -> 10 - abs(i-idx))")) \
.withColumn('sum_weights', expr("aggregate(weights, 0D, (acc,x) -> acc+x)")) \
.withColumn("vals", expr("""
aggregate(
zip_with(data, weights, (x,y) -> (x.val1*y as val1, x.val2*y as val2)),
(0D as val1, 0D as val2),
(acc,x) -> (acc.val1 + x.val1, acc.val2 + x.val2),
acc -> (acc.val1/sum_weights as weighted_val1, acc.val2/sum_weights as weighted_val2)
)
""")).select(*df.columns, "vals.*")
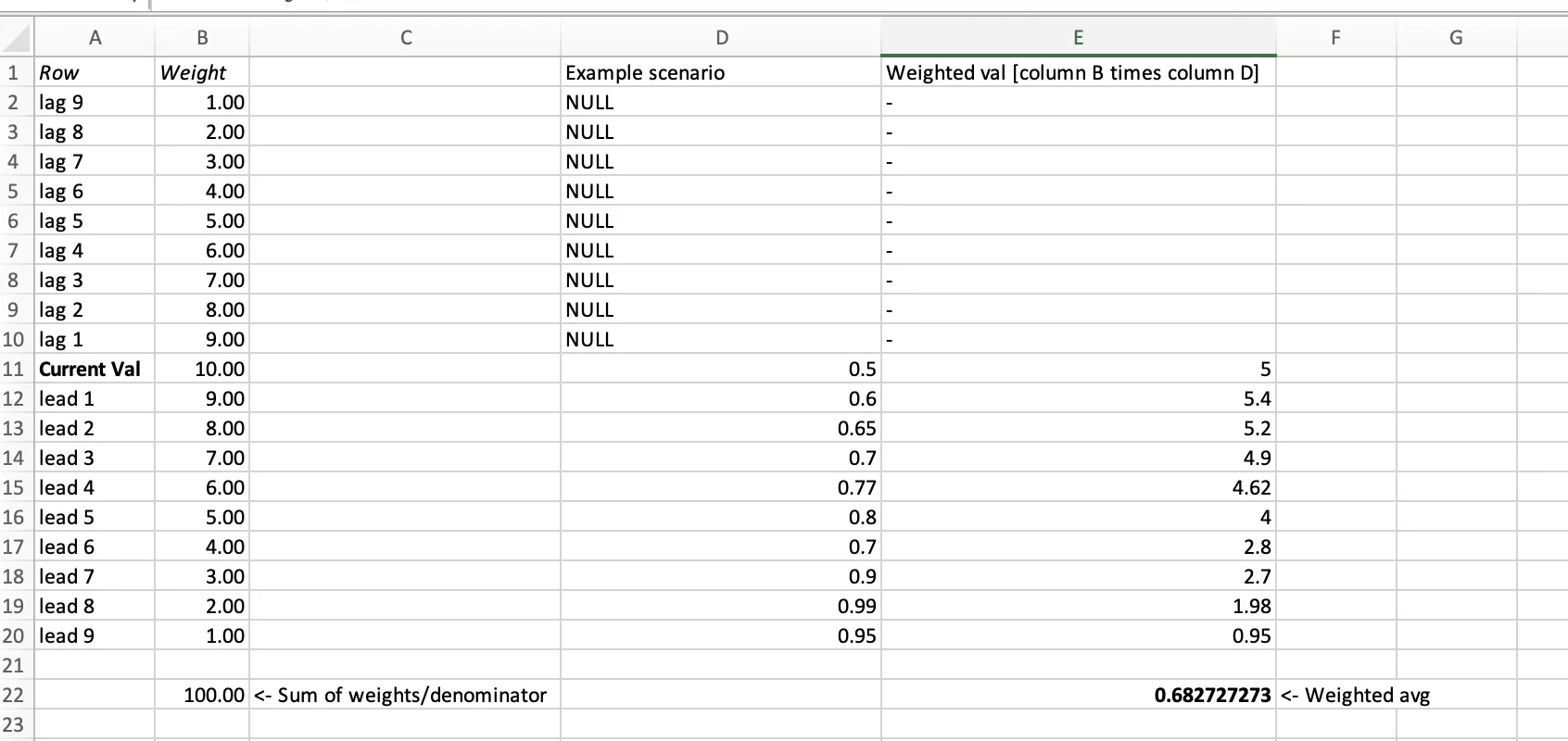 我知道我可以在SQL中做到这一点(我可以将数据框保存为临时视图),但由于我必须对多个列执行此滚动平均值(完全相同的逻辑),所以如果我能在Pyspark中做到这一点,最理想的情况是我将能够编写一个for循环,然后对每个列执行它。此外,我希望能够高效地完成此操作。我已经阅读了许多关于滚动平均数的线程,但我认为这种情况略有不同。
我知道我可以在SQL中做到这一点(我可以将数据框保存为临时视图),但由于我必须对多个列执行此滚动平均值(完全相同的逻辑),所以如果我能在Pyspark中做到这一点,最理想的情况是我将能够编写一个for循环,然后对每个列执行它。此外,我希望能够高效地完成此操作。我已经阅读了许多关于滚动平均数的线程,但我认为这种情况略有不同。