例如,我有这样一个数据集:
test = spark.createDataFrame([
(0, 1, 5, "2018-06-03", "Region A"),
(1, 1, 2, "2018-06-04", "Region B"),
(2, 2, 1, "2018-06-03", "Region B"),
(3, 3, 1, "2018-06-01", "Region A"),
(3, 1, 3, "2018-06-05", "Region A"),
])\
.toDF("orderid", "customerid", "price", "transactiondate", "location")
test.show()
我可以通过以下方法获取客户区域订单计数矩阵:
overall_stat = test.groupBy("customerid").agg(count("orderid"))\
.withColumnRenamed("count(orderid)", "overall_count")
temp_result = test.groupBy("customerid").pivot("location").agg(count("orderid")).na.fill(0).join(overall_stat, ["customerid"])
for field in temp_result.schema.fields:
if str(field.name) not in ['customerid', "overall_count", "overall_amount"]:
name = str(field.name)
temp_result = temp_result.withColumn(name, col(name)/col("overall_count"))
temp_result.show()
数据应该是这个样子的:
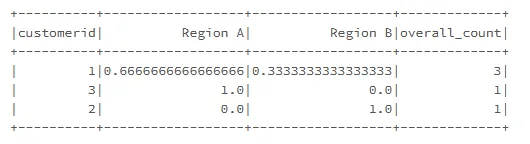
现在,我想通过 overall_count 计算加权平均值,该怎么做?
结果应为区域 A 的 (0.66*3+1*1)/4,区域 B 的 (0.33*3+1*1)/4
我的想法:
当然可以把数据转成 Python/Pandas 来完成一些计算,但在什么情况下应该使用 Pyspark 呢?
我可以得到类似于以下的结果
temp_result.agg(sum(col("Region A") * col("overall_count")), sum(col("Region B")*col("overall_count"))).show()
但是这种方法并不太合适,特别是在需要计算多个region的情况下。