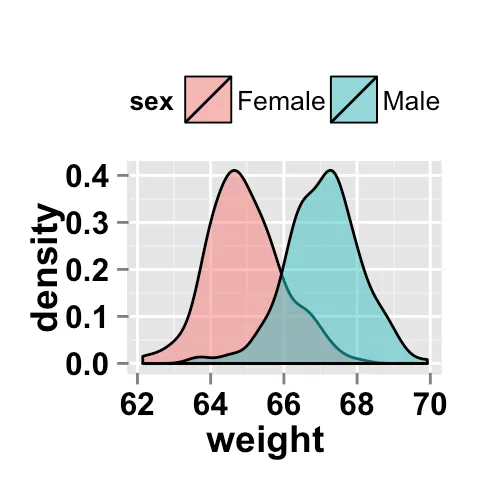
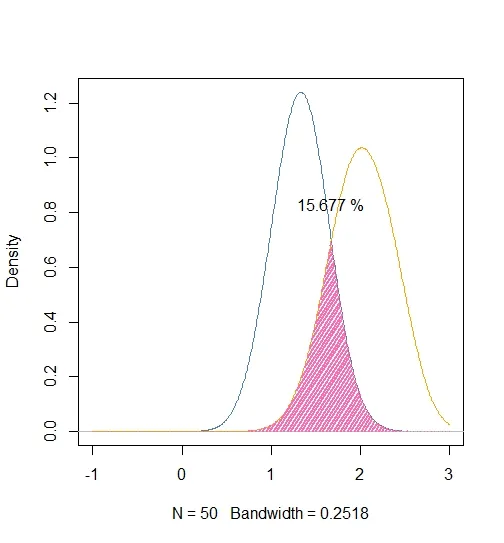
首先,准备一些数据以供使用。这里,我们将查看内置的iris数据集中两个植物物种的花瓣宽度。
dat <- droplevels(with(iris, iris[Species %in% c("versicolor", "virginica"), ]))
library(ggplot2)
ggplot(dat, aes(Petal.Width, fill=Species)) +
geom_density(alpha=0.5)
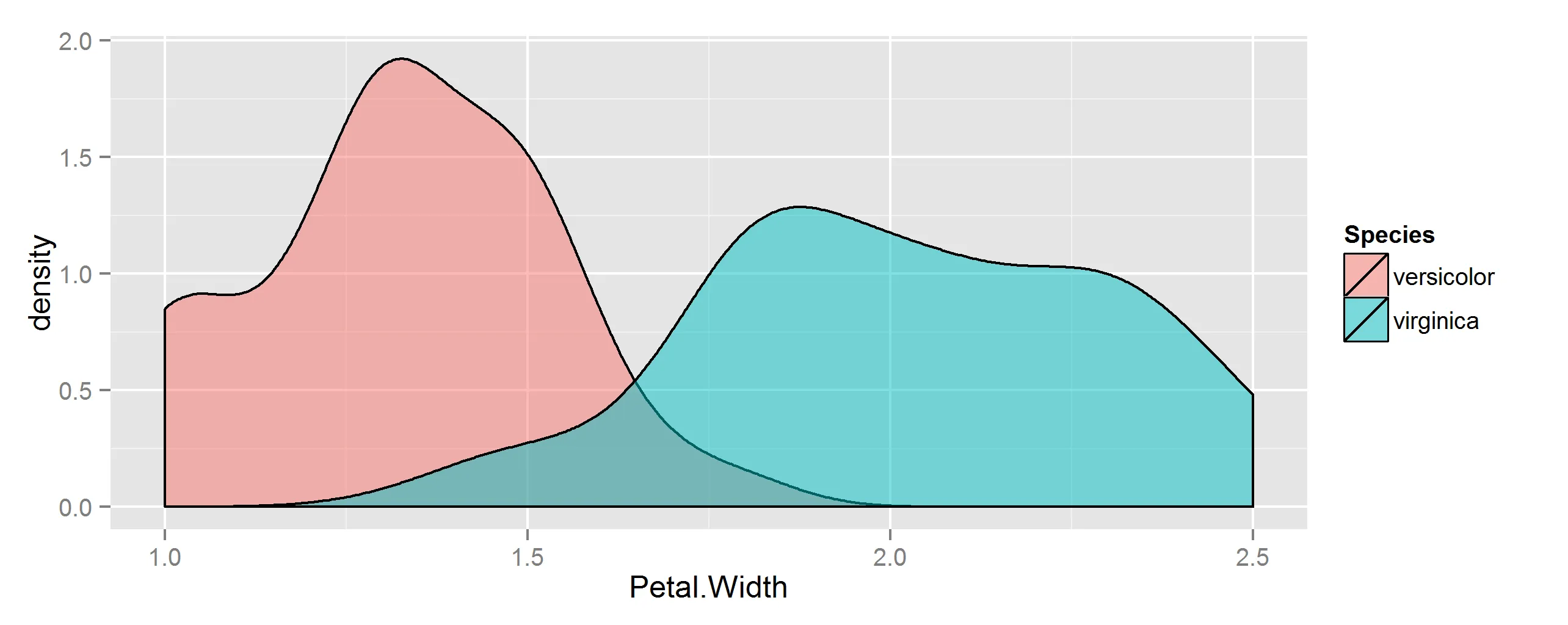
要找到交集的区域,您可以使用approxfun逼近描述重叠部分的函数。 然后对其进行积分以得到该区域的面积。 由于它们是密度曲线,因此它们的面积为1(左右),因此积分将是重叠百分比。
ps <- lapply(split(dat, dat$Species), function(x) {
dens <- density(x$Petal.Width)
data.frame(x=dens$x, y=dens$y)
})
fs <- sapply(ps, function(x) approxfun(x$x, x$y, yleft=0, yright=0))
f <- function(x) fs[[1]](x) - fs[[2]](x)
meet <- uniroot(f, interval=c(1, 2))$root
ps1 <- is.na(cut(ps[[1]]$x, c(-Inf, meet)))
ps2 <- is.na(cut(ps[[2]]$x, c(Inf, meet)))
shared <- rbind(ps[[1]][ps1,], ps[[2]][ps2,])
f <- with(shared, approxfun(x, y, yleft=0, yright=0))
xs <- seq(0, 3, len=1000)
plot(xs, f(xs), type="l", col="blue", ylim=c(0, 2))
points(ps[[1]], col="red", type="l", lty=2, lwd=2)
points(ps[[2]], col="blue", type="l", lty=2, lwd=2)
polygon(c(xs, rev(xs)), y=c(f(xs), rep(0, length(xs))), col="orange", density=40)
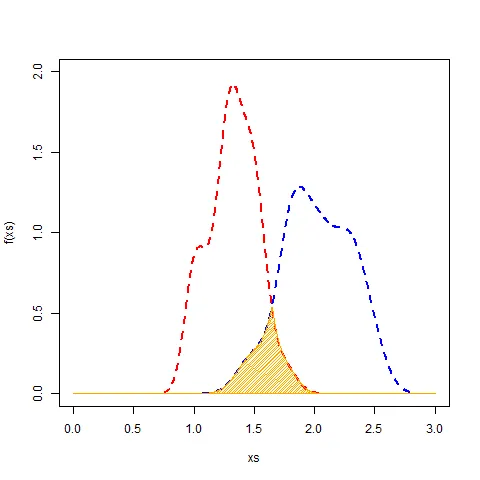
integrate(f, lower=0, upper=3)$value