我有一个包含多个列和行的数据框,在除了最左边两列之外的所有列中,都有"整数-整数"形式的数据。我想将所有这些列拆分成两个列,每个整数在自己的单元格中,并删除破折号。
我试图按照Pandas Dataframe: Split multiple columns each into two columns中的答案操作,但似乎它们是在一个元素后拆分,而我想在“ - ”上拆分。
例如,假设我有一个数据框:
感谢您的任何帮助。
我试图按照Pandas Dataframe: Split multiple columns each into two columns中的答案操作,但似乎它们是在一个元素后拆分,而我想在“ - ”上拆分。
例如,假设我有一个数据框:
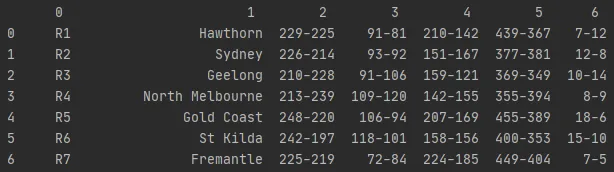
感谢您的任何帮助。
print(df.head(3).to_dict())是什么? - jezraeldf.columns = range(len(df.columns))分配范围。 - jezrael