我有一个输入数据框:
import pandas as pd
# Define the input data
data = {
'ID': [500, 200, 300],
'A': [3, 3, ''],
'B': [3, 1, ''],
'C': [2, '' ,''],
'D': ['', 2, 1],
'E': ['', '',2 ],
}
# Convert the input data to a Pandas DataFrame
df = pd.DataFrame(data)
输入表格
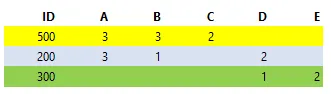
我需要将这个输入转换成下面的输出示例中所示:
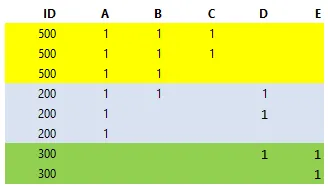
如果您有任何想法,请分享。非常感谢!