如何统计以下数组中数字0和1的数量?
y = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
y.count(0) 的输出为:
numpy.ndarray对象没有count属性。
如何统计以下数组中数字0和1的数量?
y = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
y.count(0) 的输出为:
numpy.ndarray对象没有count属性。
numpy.unique:import numpy
a = numpy.array([0, 3, 0, 1, 0, 1, 2, 1, 0, 0, 0, 0, 1, 3, 4])
unique, counts = numpy.unique(a, return_counts=True)
>>> dict(zip(unique, counts))
{0: 7, 1: 4, 2: 1, 3: 2, 4: 1}
非numpy方法使用collections.Counter;
import collections, numpy
a = numpy.array([0, 3, 0, 1, 0, 1, 2, 1, 0, 0, 0, 0, 1, 3, 4])
counter = collections.Counter(a)
>>> counter
Counter({0: 7, 1: 4, 3: 2, 2: 1, 4: 1})
dict(zip(*numpy.unique(a, return_counts=True)))。 - Seppo Enarvicollections.Counter则运行良好。 - Ivan Novikov那么使用 numpy.count_nonzero 怎么样?
>>> import numpy as np
>>> y = np.array([1, 2, 2, 2, 2, 0, 2, 3, 3, 3, 0, 0, 2, 2, 0])
>>> np.count_nonzero(y == 1)
1
>>> np.count_nonzero(y == 2)
7
>>> np.count_nonzero(y == 3)
3
numpy.ndarray会起作用。 - LYu个人而言,我会选择:(y == 0).sum() 和 (y == 1).sum()
例如:
import numpy as np
y = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
num_zeros = (y == 0).sum()
num_ones = (y == 1).sum()
sum(vector==value)。 - ePi272314(y ==“A”) 返回一个 bool 值数组。由于在Python中布尔值等于0和1,因此它们可以求和:(y ==“A”).sum() 将返回数组 y 中 A 的计数。 - natka_m对于您的情况,您也可以查看numpy.bincount
In [56]: a = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
In [57]: np.bincount(a)
Out[57]: array([8, 4]) #count of zeros is at index 0, i.e. 8
#count of ones is at index 1, i.e. 4
np.bincount([0, 0.5, 1.1]) == array([2, 1]) (2)如果您有一个包含大整数的数组,则会得到一个很长的输出,例如,len(np.bincount([1000])) == 1001。 - icemtela = np.array([0, 0, 0, 2, 0, 2, 2, 0, 0, 0, 0, 2]),则会得到[8 0 4]。因此,对于1,它将在结果中放置0。 - Ali_Shy = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
如果你知道它们只是0和1:
np.sum(y)
这个函数可以给你一个数的数量。 np.sum(1-y) 则会给出零的数量。
稍微通用一些,如果你想计算0而不是零(但也可能是2或3):
np.count_nonzero(y)
提供非零数的数量。
但如果你需要更复杂的内容,我认为numpy不会提供一个良好的count选项。在这种情况下,请使用collections:
import collections
collections.Counter(y)
> Counter({0: 8, 1: 4})
这类似于一个字典
collections.Counter(y)[0]
> 8
y 转换为列表 l,然后执行 l.count(1) 和 l.count(0)。>>> y = numpy.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
>>> l = list(y)
>>> l.count(1)
4
>>> l.count(0)
8
如果您确切地知道您要查找的数字,您可以使用以下内容:
lst = np.array([1,1,2,3,3,6,6,6,3,2,1])
(lst == 2).sum()
返回您的数组中2出现的次数。
len使用len可能是另一种选择。
A = np.array([1,0,1,0,1,0,1])
假设我们想要统计数字 0 出现的次数。
A[A==0] # Return the array where item is 0, array([0, 0, 0])
len将其包装起来。len(A[A==0]) # 3
len(A[A==1]) # 4
len(A[A==7]) # 0, because there isn't such item.
说实话,我觉得最容易的方法是将其转换为pandas Series或DataFrame:
import pandas as pd
import numpy as np
df = pd.DataFrame({'data':np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])})
print df['data'].value_counts()
或者使用罗伯特·穆尔建议的这个简洁的一行代码:
pd.Series([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1]).value_counts()
pd.Series([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1]).value_counts() - Robert Muil如果你对速度最快的执行感兴趣,提前知道要查找哪个值,并且你的数组是1D的,或者你对展平后的数组结果感兴趣(在这种情况下,函数的输入应该是np.ravel(arr)而不仅仅是arr),那么Numba就是你的好朋友:
import numba as nb
@nb.jit
def count_nb(arr, value):
result = 0
for x in arr:
if x == value:
result += 1
return result
或者,对于非常大的数组可以受益于并行化的情况:
@nb.jit(parallel=True)
def count_nbp(arr, value):
result = 0
for i in nb.prange(arr.size):
if arr[i] == value:
result += 1
return result
这些可以与 np.count_nonzero() 进行基准测试(它也有一个创建临时数组的问题——这是在 Numba 解决方案中避免的),以及一个基于 np.unique() 的解决方案(与其他解决方案相反,实际上计算所有唯一值的计数)。
import numpy as np
def count_np(arr, value):
return np.count_nonzero(arr == value)
import numpy as np
def count_np_uniq(arr, value):
uniques, counts = np.unique(a, return_counts=True)
counter = dict(zip(uniques, counts))
return counter[value] if value in counter else 0
自从Numba支持"类型化"字典后,现在可以编写一个函数来计算所有元素的出现次数。与np.unique()直接竞争,因为它能够一次性计算所有值的数量。以下提供了一个版本,最终只返回单个值的元素数量(为了比较目的,类似于count_np_uniq()所做的)。
@nb.jit
def count_nb_dict(arr, value):
counter = {arr[0]: 1}
for x in arr:
if x not in counter:
counter[x] = 1
else:
counter[x] += 1
return counter[value] if value in counter else 0
def gen_input(n, a=0, b=100):
return np.random.randint(a, b, n)
以下图表显示了计时信息(第二行图表为更快的方法进行了放大):
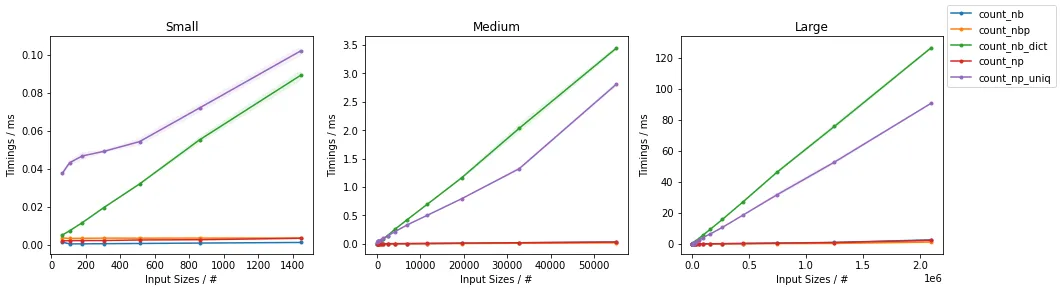
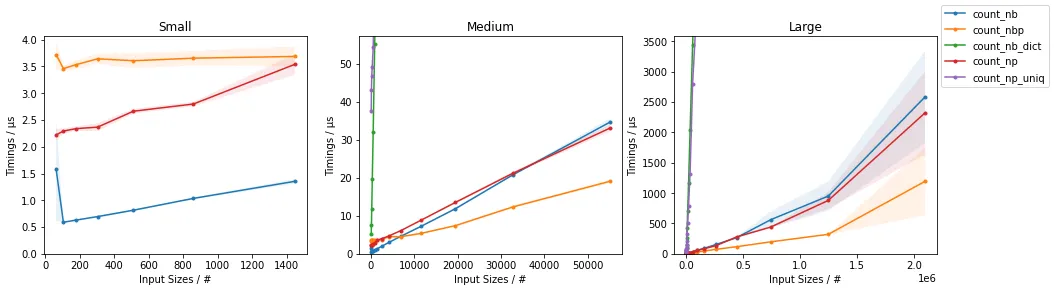
结果显示,对于较小的输入,基于Numba的简单解决方案最快,而并行化版本对于较大的输入最快。NumPy版本在所有规模下的速度都相当快。
当一个人想要计算数组中的所有值时,np.unique() 比使用Numba手动实现的解决方案对于足够大的数组更有效。
编辑:似乎NumPy的解决方案在最近的版本中变得更快了。在以前的版本中,简单的Numba解决方案在任何输入大小下都比NumPy的方法表现更好。
完整代码在此处可用。
numpy.count_nonzero函数。 - Mong H. Ng