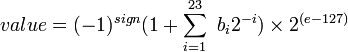这更像是一个数学问题。尽管如此,我正在寻找解决它的伪代码算法。
给定一维坐标系和若干点。点的坐标可能是浮点数。
现在我正在寻找一个因子来缩放这个坐标系,使得所有的点都在固定的数字上(即整数坐标)。
如果我没有弄错的话,只要点的数量不是无限的,就应该有一个解决方案。
如果我错了,这个问题没有解析解,那么我对一个尽可能接近的算法感兴趣。(即坐标看起来像15.0001)
如果你对具体的问题感兴趣: 我想克服Adobe Flash中著名的像素捕捉问题,当整个舞台被缩放时,会剪切位图边界的半个像素。我想找到一个理想的舞台缩放因子,使我的位图被放置在整个(屏幕)像素坐标上。
由于我在舞台上放置了两个位图,每个方向(x,y)的点数将为4。
谢谢!
给定一维坐标系和若干点。点的坐标可能是浮点数。
现在我正在寻找一个因子来缩放这个坐标系,使得所有的点都在固定的数字上(即整数坐标)。
如果我没有弄错的话,只要点的数量不是无限的,就应该有一个解决方案。
如果我错了,这个问题没有解析解,那么我对一个尽可能接近的算法感兴趣。(即坐标看起来像15.0001)
如果你对具体的问题感兴趣: 我想克服Adobe Flash中著名的像素捕捉问题,当整个舞台被缩放时,会剪切位图边界的半个像素。我想找到一个理想的舞台缩放因子,使我的位图被放置在整个(屏幕)像素坐标上。
由于我在舞台上放置了两个位图,每个方向(x,y)的点数将为4。
谢谢!