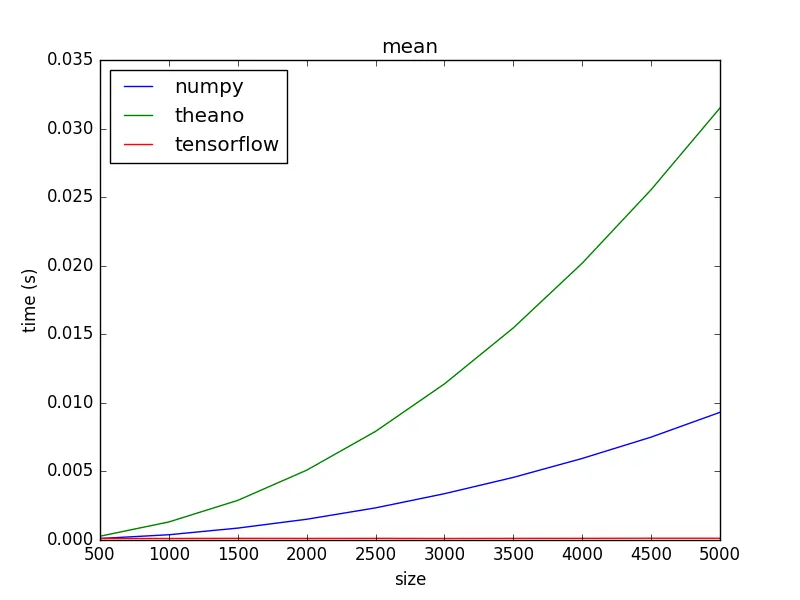
我正在使用numpy计算平均值和标准差。为了提高性能,我尝试使用Tensorflow进行相同的操作,但是Tensorflow至少慢了约10倍。我在Tensorflow中尝试了两种方法(如下所示)。第一种方法使用
我尝试过CPU和GPU;numpy始终更快。
我使用
为什么Tensorflow更慢?我认为这可能是由于将数据传输到GPU,但即使对于非常小的数据集(传输时间应该可以忽略不计),并且仅使用CPU时,TF也较慢。这是由于初始化TF所需的开销时间吗?
tf.nn.moments(),它有一个错误会导致方差有时返回负值。在第二种方法中,我通过其他Tensorflow函数计算方差。我尝试过CPU和GPU;numpy始终更快。
我使用
time.time()而不是time.clock()来测量使用GPU时的墙钟时间。为什么Tensorflow更慢?我认为这可能是由于将数据传输到GPU,但即使对于非常小的数据集(传输时间应该可以忽略不计),并且仅使用CPU时,TF也较慢。这是由于初始化TF所需的开销时间吗?
import tensorflow as tf
import numpy
import time
import math
class Timer:
def __enter__(self):
self.start = time.time()
return self
def __exit__(self, *args):
self.end = time.time()
self.interval = self.end - self.start
inData = numpy.random.uniform(low=-1, high=1, size=(40000000,))
with Timer() as t:
mean = numpy.mean(inData)
print 'python mean', mean, 'time', t.interval
with Timer() as t:
stdev = numpy.std(inData)
print 'python stdev', stdev, 'time', t.interval
# Approach 1 (Note tf.nn.moments() has a bug)
with Timer() as t:
with tf.Graph().as_default():
meanTF, varianceTF = tf.nn.moments(tf.constant(inData), axes=[0])
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
mean, variance = sess.run([meanTF, varianceTF])
sess.close()
print 'variance', variance
stdev = math.sqrt(variance)
print 'tensorflow mean', mean, 'stdev', stdev, 'time', t.interval
# Approach 2
with Timer() as t:
with tf.Graph().as_default():
inputVector = tf.constant(inData)
meanTF = tf.reduce_mean(inputVector)
length = tf.size(inputVector)
varianceTF = tf.divide(tf.reduce_sum(tf.squared_difference(inputVector, mean)), tf.to_double(length))
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
mean, variance = sess.run([meanTF, varianceTF])
sess.close()
print 'variance', variance
stdev = math.sqrt(variance)
print 'tensorflow mean', mean, 'stdev', stdev, 'time', t.interval