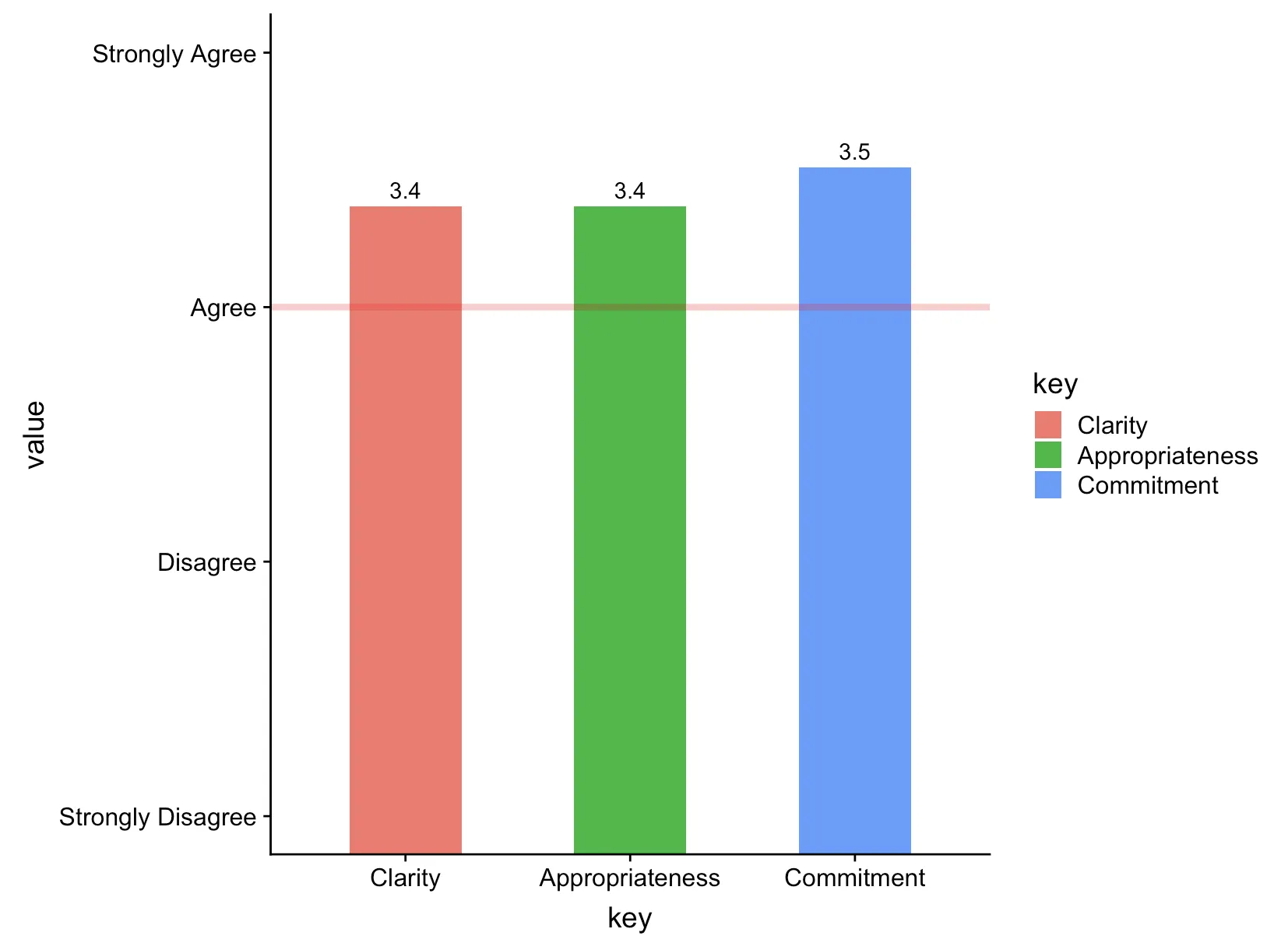
我有一些调查数据,人们回答了不同陈述的强烈同意、同意、不同意和强烈不同意程度。他们的回答可以是介于1到4之间的任何值(包括小数)(1 = 强烈不同意,2 = 不同意,等等...)。
我想通过绘制每个变量的平均值来总结这些数据,并在条形图中更改Y轴标签,使其不是数字值,而是锚点处的标签,如1 = 强烈不同意,2 = 不同意等等。
鉴于下面所包含的数据,我可以使用以下代码完成此操作:
我想通过绘制每个变量的平均值来总结这些数据,并在条形图中更改Y轴标签,使其不是数字值,而是锚点处的标签,如1 = 强烈不同意,2 = 不同意等等。
鉴于下面所包含的数据,我可以使用以下代码完成此操作:
ggplot(data = data, aes(x=factor(key), y=value, fill=key)) +
stat_summary(fun.y="mean", geom="bar", width = 0.5) +
stat_summary(aes(label=round(..y..,1)), fun.y="mean", geom="text", vjust = -0.5) +
geom_hline(yintercept = 3, linetype="solid", color = "red", size=1.5, alpha=0.25) +
scale_y_discrete(limits=c("Strongly Disagree", "Disagree", "Agree", "Strongly Agree"))
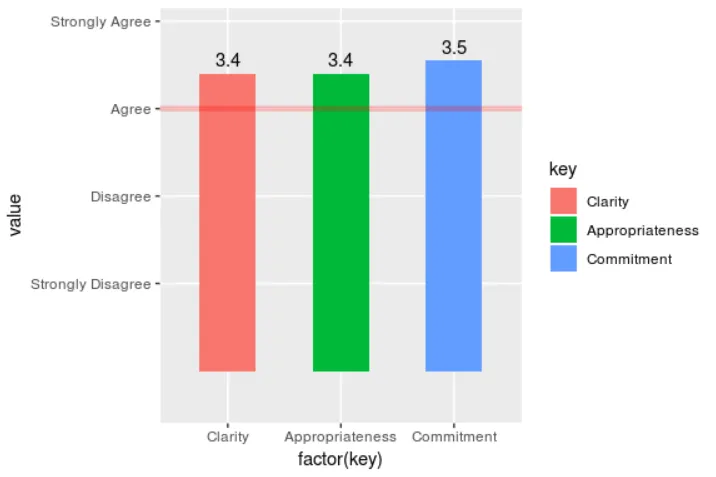
这基本符合我的需求,但我希望Y轴从1 = 强烈反对开始,而不是从0开始。
我想过可以将所有数字响应减1,但是每个条形的平均分标签将不正确。
唯一的限制是我希望在ggplot中完成这个任务,而且最好不要通过重新整理原始数据来实现。 我有另一个类似的图表,在其中使用了facet_wrap()为数据集中的每个组(未包括变量)创建相同的图表。
我已经搜索了很多,但似乎改变ggplot轴的起始点并不是通常建议的事情。 但是,在这种情况下,我认为这是可以接受的。
data <- structure(list(key = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L), .Label = c("Clarity", "Appropriateness", "Commitment"
), class = "factor"), value = c(NA, 3.33333333333333, 3.33333333333333,
4, 4, 3, 4, NA, 3, NA, 3, 4, NA, NaN, 3, 2.66666666666667, 3,
NA, 3.33333333333333, 3.66666666666667, 3.66666666666667, 4,
NA, 3, 4, 3.66666666666667, 3, 2.66666666666667, 3, 4, 4, 3,
3, NaN, 3, 4, 3, 4, 3, 4, 4, 2.33333333333333, 3, 4, 4, 3, 4,
3, 3, 3.33333333333333, 3, 4, 3, NA, 2.66666666666667, 3.33333333333333,
4, 2.33333333333333, 3.66666666666667, 4, 4, 3, NA, 3, 4, 3.2,
4, 3, 4, NA, 3.2, NA, 3, 4, NA, 4, 3, 3.4, 3, NA, 2.8, 3.6, 3.6,
3.8, NA, 3, 3.4, 3.2, 3, 3, 3.4, 3.8, 3.6, 3, 3, NaN, 2.4, 4,
3, 3.2, 3.2, 4, 4, 2.6, 3.8, 4, 4, 3.6, 3.2, 3, 3, 4, 2.8, 4,
3, NA, 3.4, 3.4, 4, 2.6, 3.8, 4, 3.4, 3, NA, 2.33333333333333,
4, 3.66666666666667, 4, 3, 4, NA, 3.33333333333333, NA, 4, 4,
NA, 4, 4, 2.33333333333333, 3.66666666666667, NA, 3, 4, 4, 4,
NA, 3.33333333333333, 3, 4, 3.33333333333333, 3.66666666666667,
3.33333333333333, 4, 4, 2.33333333333333, 3.66666666666667, NaN,
3, 4, 3, 3, 4, 3.66666666666667, 4, 3.33333333333333, 4, 3.66666666666667,
4, 4, 4, 3.66666666666667, 3, 3.33333333333333, 3.66666666666667,
3.66666666666667, 2.66666666666667, NA, 2.33333333333333, 3,
4, 3, 3.66666666666667, 4, 4, 4)), class = "data.frame", row.names = c(NA,
-186L))