我正在尝试从这个数据框中获取一个频率表:
tmp2 <- structure(list(a1 = c(1L, 0L, 0L), a2 = c(1L, 0L, 1L),
a3 = c(0L, 1L, 0L), b1 = c(1L, 0L, 1L),
b2 = c(1L, 0L, 0L), b3 = c(0L, 1L, 1L)),
.Names = c("a1", "a2", "a3", "b1", "b2", "b3"),
class = "data.frame", row.names = c(NA, -3L))
tmp2 <- read.csv("tmp2.csv", sep=";")
tmp2
> tmp2
a1 a2 a3 b1 b2 b3
1 1 1 0 1 1 0
2 0 0 1 0 0 1
3 0 1 0 1 0 1
我尝试获取以下频率表:
table(tmp2[,1:3], tmp2[,4:6])
但是我得到了:
在sort.list(y)中出现错误:'x'必须是原子的,以便进行'sort.list'
您是否在列表上调用了'sort'?
预期输出:
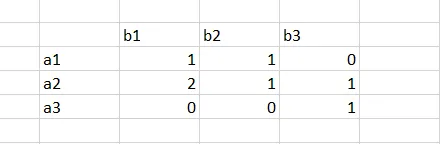
信息:不一定需要正方形矩阵,例如我应该可以将b4 b5相加并保留a1 a2 a3。
a2 b1等于 2? - akruncrossprod在这里也可能很有用;crossprod(as.matrix(tmp2[1:3]), as.matrix(tmp2[4:6]))。 - alexis_laz