我有一个电子书文本文件,名为 Frankenstein.txt,我想知道小说中每个字母出现的次数。
我的设置:
我导入了文本文件,像这样得到一个字符向量 character_array:
string <- readChar("Frankenstein.txt", filesize)
character_array <- unlist(strsplit(string, ""))
character_array 给我类似这样的东西。
"F" "r" "a" "n" "k" "e" "n" "s" "t" "e" "i" "n" "\r", ...
我的目标:
我想要获取文本文件中每个字符出现次数的计数。换句话说,我想要针对unique(character_array)获取每个唯一字符的计数。
[1] "F" "r" "a" "n" "k" "e" "s" "t" "i" "\r" "\n" "b" "y" "M"
[15] " " "W" "o" "l" "c" "f" "(" "G" "d" "w" ")" "S" "h" "C"
[29] "O" "N" "T" "E" "L" "1" "2" "3" "4" "p" "5" "6" "7" "8"
[43] "9" "0" "_" "." "v" "," "g" "P" "u" "D" "—" "Y" "j" "m"
[57] "I" "z" "?" ";" "x" "q" "B" "U" "’" "H" "-" "A" "!" ":"
[71] "R" "J" "“" "”" "æ" "V" "K" "[" "]" "‘" "ê" "ô" "é" "è"
我的尝试
当我调用plot(as.factor(character_array))时,我会得到一个漂亮的图表,可以在视觉上给我想要的结果。
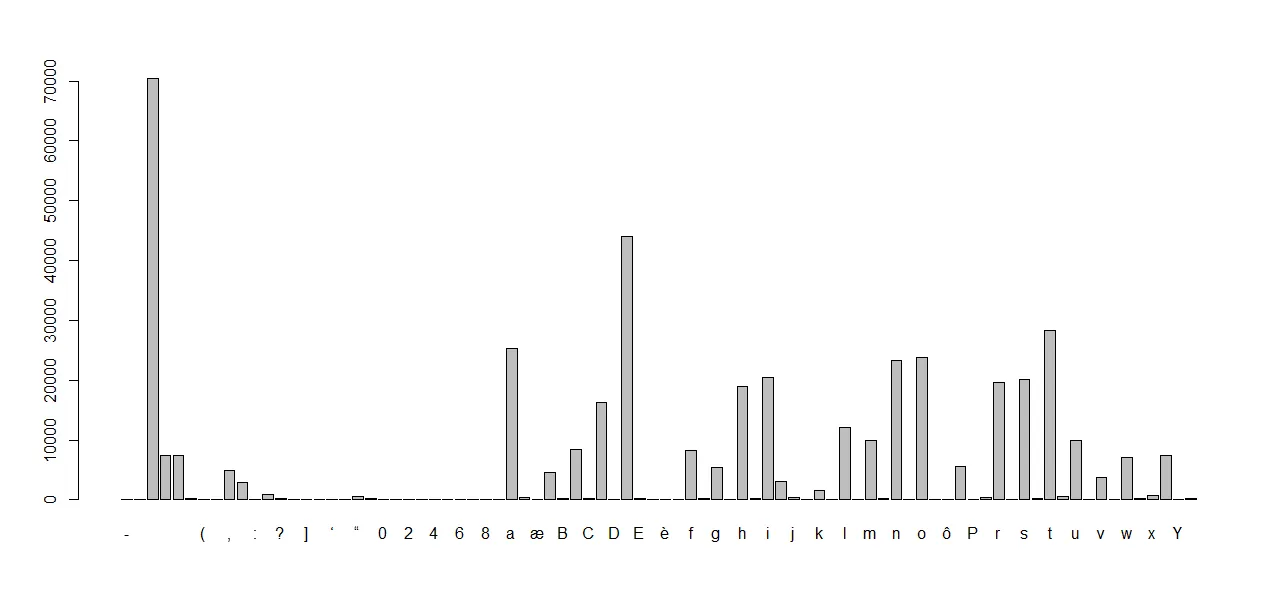 然而,我需要获取每个字符的确切值。我希望有像2D数组这样的东西:
然而,我需要获取每个字符的确切值。我希望有像2D数组这样的东西:
[,1] [,2] [,3] [,4] ...
[1,] "a" "A" "b" "B" ...
[2,] "1202" "50" "12" "9" ...
table()函数。 - jogosummary(as.factor(character_array))。 - Rohit