我有一个数据集,其中一些列的值是相同的,但是其他列的值不同。我需要删除重复项,其中较低级别(Level2、Level3和Level4)的SubCategory“IS NOT NULL”,但其对应的“重复伙伴”(按[SubCategory Level 1 ID]、[Product Category]和[Product Name]分组)具有相同的较低级别SubCategory -“ IS NULL”。根据下表,我需要删除ID为2、4、6和9的行(请参见以红色字体突出显示的部分)。
我尝试使用Dense_Rank、Rank和Row_Number函数与Partition By,但这并没有给我所需的输出。也许我需要使用它们的组合...
例如:RowID 1和2按[Product Category]、[Product Name]、[Category Level 1]进行了重复。 “Category Level 1”只是“Product Category”的ID。当RowID 2有时,我需要删除RowID 2,因为它对应的重复伙伴RowID 1没有分配“Category Level 3”。相同的逻辑适用于RowID 9和10,但此时RowID 9具有“Category Level 2”,而Row 10则没有。如果两个重复项(RowID 1和2)都分配了“Category Level 3”,我们就不需要删除任何一个重复项。
图片链接: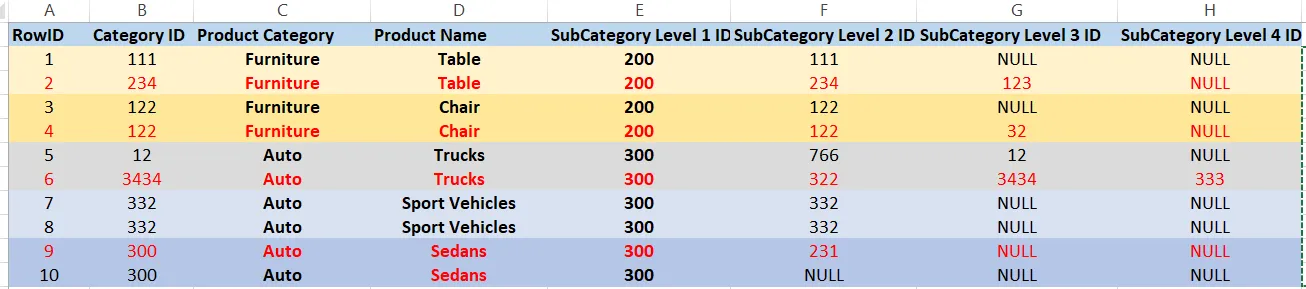
我尝试使用Dense_Rank、Rank和Row_Number函数与Partition By,但这并没有给我所需的输出。也许我需要使用它们的组合...
例如:RowID 1和2按[Product Category]、[Product Name]、[Category Level 1]进行了重复。 “Category Level 1”只是“Product Category”的ID。当RowID 2有时,我需要删除RowID 2,因为它对应的重复伙伴RowID 1没有分配“Category Level 3”。相同的逻辑适用于RowID 9和10,但此时RowID 9具有“Category Level 2”,而Row 10则没有。如果两个重复项(RowID 1和2)都分配了“Category Level 3”,我们就不需要删除任何一个重复项。
图片链接:
IF OBJECT_ID('tempdb..#Category', 'U') IS NOT NULL
DROP TABLE #Category;
GO
CREATE TABLE #Category
(
RowID INT NOT NULL,
CategoryID INT NOT NULL,
ProductCategory VARCHAR(100) NOT NULL,
ProductName VARCHAR(100) NOT NULL,
[SubCategory Level 1 ID] INT NOT NULL,
[SubCategory Level 2 ID] INT NULL,
[SubCategory Level 3 ID] INT NULL,
[SubCategory Level 4 ID] INT NULL
);
INSERT INTO #Category (RowID, CategoryID, ProductCategory, ProductName, [SubCategory Level 1 ID], [SubCategory Level 2 ID], [SubCategory Level 3 ID], [SubCategory Level 4 ID])
VALUES
(1, 111, 'Furniture', 'Table', 200, 111, NULL, NULL),
(2, 234, 'Furniture', 'Table', 200, 234, 123, NULL),
(3, 122, 'Furniture', 'Chair', 200, 122, NULL, NULL),
(4, 122, 'Furniture', 'Chair', 200, 122, 32, NULL),
(5, 12, 'Auto', 'Trucks', 300, 766, 12, NULL),
(6, 3434, 'Auto', 'Trucks', 300, 322, 3434, 333),
(7, 332, 'Auto', 'Sport Vehicles', 300, 332, NULL, NULL),
(8, 332, 'Auto', 'Sport Vehicles', 300, 332, NULL, NULL),
(9, 300, 'Auto', 'Sedans', 300, 231, NULL, NULL),
(10, 300, 'Auto', 'Sedans', 300, NULL, NULL, NULL),
(11, 300, 'Auto', 'Cabriolet', 300, 456, 688, NULL),
(12, 300, 'Auto', 'Cabriolet', 300, 456, 976, NULL),
(13, 300, 'Auto', 'Motorcycles', 300, 456, 235, 334),
(14, 300, 'Auto', 'Motorcycles', 300, 456, 235, 334);
SELECT * FROM #Category;
-- ADD YOU CODE HERE TO RETURN the following RowIDs: 2, 4, 6, 9
{kind=link}