要从SQL Server的表中删除重复行,您需要按照以下步骤操作:
- 使用GROUP BY子句或ROW_NUMBER()函数查找重复行。
- 使用DELETE语句删除重复行。
设置样例表
DROP TABLE IF EXISTS contacts;
CREATE TABLE contacts(
contact_id INT IDENTITY(1,1) PRIMARY KEY,
first_name NVARCHAR(100) NOT NULL,
last_name NVARCHAR(100) NOT NULL,
email NVARCHAR(255) NOT NULL,
);
插入数值
INSERT INTO contacts
(first_name,last_name,email)
VALUES
('Syed','Abbas','syed.abbas@example.com'),
('Catherine','Abel','catherine.abel@example.com'),
('Kim','Abercrombie','kim.abercrombie@example.com'),
('Kim','Abercrombie','kim.abercrombie@example.com'),
('Kim','Abercrombie','kim.abercrombie@example.com'),
('Hazem','Abolrous','hazem.abolrous@example.com'),
('Hazem','Abolrous','hazem.abolrous@example.com'),
('Humberto','Acevedo','humberto.acevedo@example.com'),
('Humberto','Acevedo','humberto.acevedo@example.com'),
('Pilar','Ackerman','pilar.ackerman@example.com');

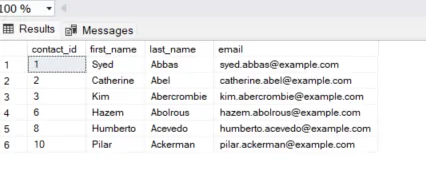
查询
SELECT
contact_id,
first_name,
last_name,
email
FROM
contacts;
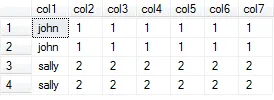
从数据表中删除重复行
WITH cte AS (
SELECT
contact_id,
first_name,
last_name,
email,
ROW_NUMBER() OVER (
PARTITION BY
first_name,
last_name,
email
ORDER BY
first_name,
last_name,
email
) row_num
FROM
contacts
)
DELETE FROM cte
WHERE row_num > 1;
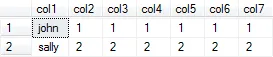
现在应该删除该记录