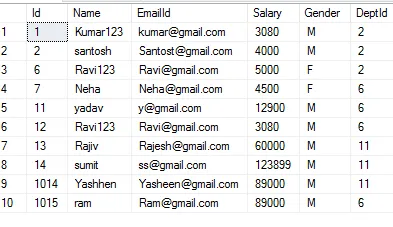
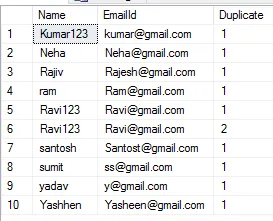
我有一个包含组织机构的 SQL Server 数据库,其中存在许多重复行。 我想运行一个 select 语句来获取所有这些重复行以及它们的数量,但也要返回与每个组织机构相关的 id 。类似于下面的语句:
SELECT orgName, COUNT(*) AS dupes
FROM organizations
GROUP BY orgName
HAVING (COUNT(*) > 1)
将返回类似于以下内容
orgName | dupes
ABC Corp | 7
Foo Federation | 5
Widget Company | 2
orgName | dupeCount | id
ABC Corp | 1 | 34
ABC Corp | 2 | 5
...
Widget Company | 1 | 10
Widget Company | 2 | 2
原因是有一张单独的用户表与这些组织相关联,我想将它们统一起来(因此删除重复项,使用户链接到相同的组织而不是重复的组织)。但我想手动处理其中的一部分,以免出错,但仍需要一条语句返回所有重复组织的ID,以便我可以查看用户列表。
on部分使用isnull()来处理可空列。 - Arif Ulusoy