我认为也许将您的两个提议简单地合并,同时放大差异以使其更加明显可能是一个选择。
以下是使用ggplot2尝试实现此目标。实际上,这比我最初想象的要复杂得多,我对结果肯定不是百分之百满意; 但也许它仍然有所帮助。欢迎评论和改进。
library(ggplot2)
library(dplyr)
gg_color_hue <- function(n) {
hues = seq(15, 375, length=n+1)
hcl(h=hues, l=65, c=100)[1:n]
}
set.seed(1)
n <- 2000
x1 <- rlnorm(n, 0, 1)
x2 <- rlnorm(n, 0, 1.1)
df <- bind_rows(data.frame(sample=1, x=x1), data.frame(sample=2, x=x2)) %>%
mutate(sample = as.factor(sample))
g1 <- ggplot(df, aes(x=x, group=sample, colour=sample)) +
geom_density(data = df) + xlim(0, 10)
gg1 <- ggplot_build(g1)
x <- gg1$data[[1]]$x[gg1$data[[1]]$group == 1]
y1 <- gg1$data[[1]]$y[gg1$data[[1]]$group == 1]
y2 <- gg1$data[[1]]$y[gg1$data[[1]]$group == 2]
df2 <- data.frame(x = x, ymin = pmin(y1, y2), ymax = pmax(y1, y2),
side=(y1<y2), ydiff = y2-y1)
g2 <- ggplot(df2) +
geom_ribbon(aes(x = x, ymin = ymin, ymax = ymax, fill = side, alpha = 0.5)) +
geom_line(aes(x = x, y = 5 * abs(ydiff), colour = side)) +
geom_area(aes(x = x, y = 5 * abs(ydiff), fill = side, alpha = 0.4))
g3 <- g2 +
geom_density(data = df, size = 1, aes(x = x, group = sample, colour = sample)) +
xlim(0, 10) +
guides(alpha = FALSE, colour = FALSE) +
ylab("Curves: density\n Shaded area: 5 * difference of densities") +
scale_fill_manual(name = "samples", labels = 1:2, values = gg_color_hue(2)) +
scale_colour_manual(limits = list(1, 2, FALSE, TRUE), values = rep(gg_color_hue(2), 2))
print(g3)
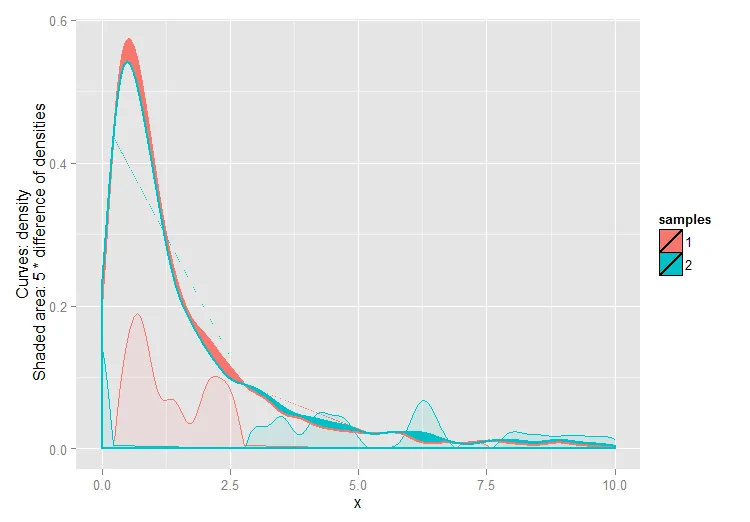
来源: SO答案1,SO答案2
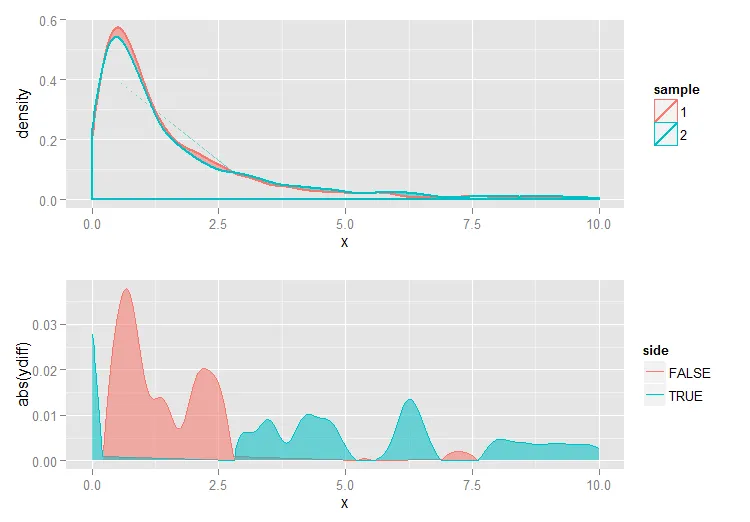
根据评论中@Gregor的建议,这里有一个版本,它在下方绘制了两个分别独立的图表,但共享相同的x轴缩放。至少图例应该明显地调整。
library(ggplot2)
library(dplyr)
library(grid)
gg_color_hue <- function(n) {
hues = seq(15, 375, length=n+1)
hcl(h=hues, l=65, c=100)[1:n]
}
set.seed(1)
n <- 2000
x1 <- rlnorm(n, 0, 1)
x2 <- rlnorm(n, 0, 1.1)
df <- bind_rows(data.frame(sample=1, x=x1), data.frame(sample=2, x=x2)) %>%
mutate(sample = as.factor(sample))
g1 <- ggplot(df, aes(x=x, group=sample, colour=sample)) +
geom_density(data = df) + xlim(0, 10)
gg1 <- ggplot_build(g1)
x <- gg1$data[[1]]$x[gg1$data[[1]]$group == 1]
y1 <- gg1$data[[1]]$y[gg1$data[[1]]$group == 1]
y2 <- gg1$data[[1]]$y[gg1$data[[1]]$group == 2]
df2 <- data.frame(x = x, ymin = pmin(y1, y2), ymax = pmax(y1, y2),
side=(y1<y2), ydiff = y2-y1)
g2 <- ggplot(df2) +
geom_ribbon(aes(x = x, ymin = ymin, ymax = ymax, fill = side, alpha = 0.5)) +
geom_density(data = df, size = 1, aes(x = x, group = sample, colour = sample)) +
xlim(0, 10) +
guides(alpha = FALSE, fill = FALSE)
g3 <- ggplot(df2) +
geom_line(aes(x = x, y = abs(ydiff), colour = side)) +
geom_area(aes(x = x, y = abs(ydiff), fill = side, alpha = 0.4)) +
guides(alpha = FALSE, fill = FALSE)
grid.draw(rbind(ggplotGrob(g2), ggplotGrob(g3), size="last"))
……或者在第二个绘图的构建中使用ydiff替换abs(ydiff):
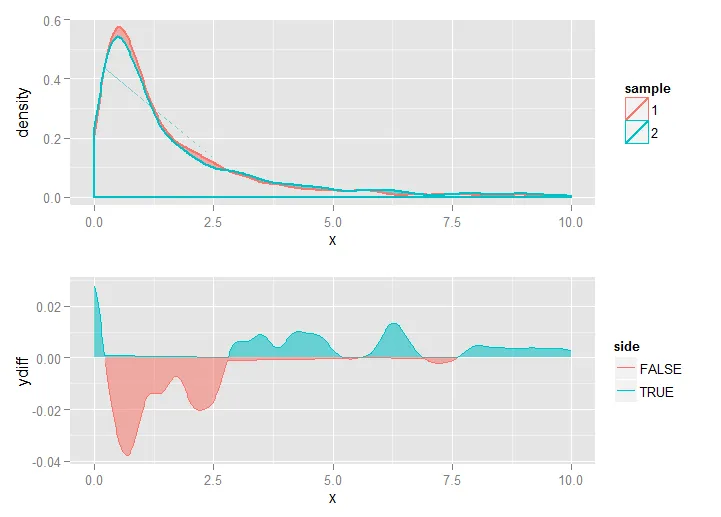
来源:SO answer 3
dput,但对于非常大的数据集,我不知道是否有任何特殊的方法。也许您可以将其放在 gist 上(同样使用dput)? - Eike P.