我有一组数据点(约10个)位于2D空间中,每个点都有一个类别标签。我希望根据现有的数据点标签对新的数据点进行分类,并为其分配属于任何特定标签类别的“概率”。
将新点标记为其最近邻居的标签是否合适(如K最近邻,K=1)?为了获取概率,我希望排列所有标签,并计算未知点与其余点之间的所有最小距离,并找到最小距离小于或等于用于标记的距离的情况的比例。
谢谢
将新点标记为其最近邻居的标签是否合适(如K最近邻,K=1)?为了获取概率,我希望排列所有标签,并计算未知点与其余点之间的所有最小距离,并找到最小距离小于或等于用于标记的距离的情况的比例。
谢谢
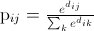 定义,其中d_ij是点i和j之间的欧几里得距离。
定义,其中d_ij是点i和j之间的欧几里得距离。