我有一个如下的二维数组:
a = np.array([[25, 83, 18, 71],
[75, 7, 0, 85],
[25, 83, 18, 71],
[25, 83, 18, 71],
[75, 48, 8, 43],
[ 7, 47, 96, 94],
[ 7, 47, 96, 94],
[56, 75, 50, 0],
[19, 49, 92, 57],
[52, 93, 58, 9]])
我想要删除某些特定值的行,例如:
b = np.array([[56, 75, 50, 0], [52, 93, 58, 9], [25, 83, 18, 71]])
这在
numpy或pandas中最有效的方法是什么? 期望输出:np.array([[75, 7, 0, 85],
[75, 48, 8, 43],
[ 7, 47, 96, 94],
[ 7, 47, 96, 94],
[19, 49, 92, 57]])
更新
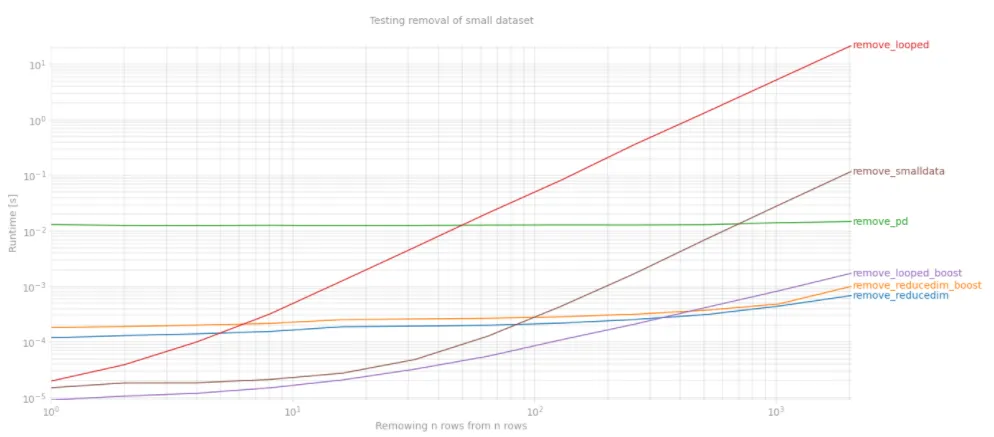
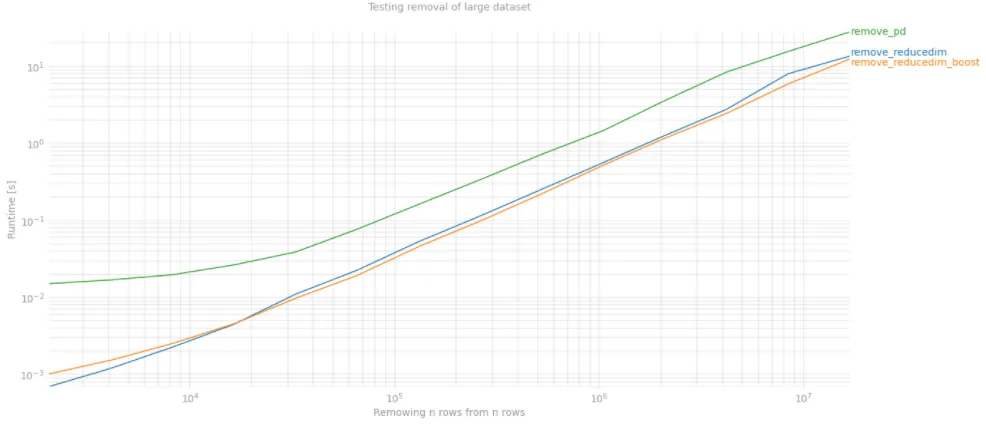
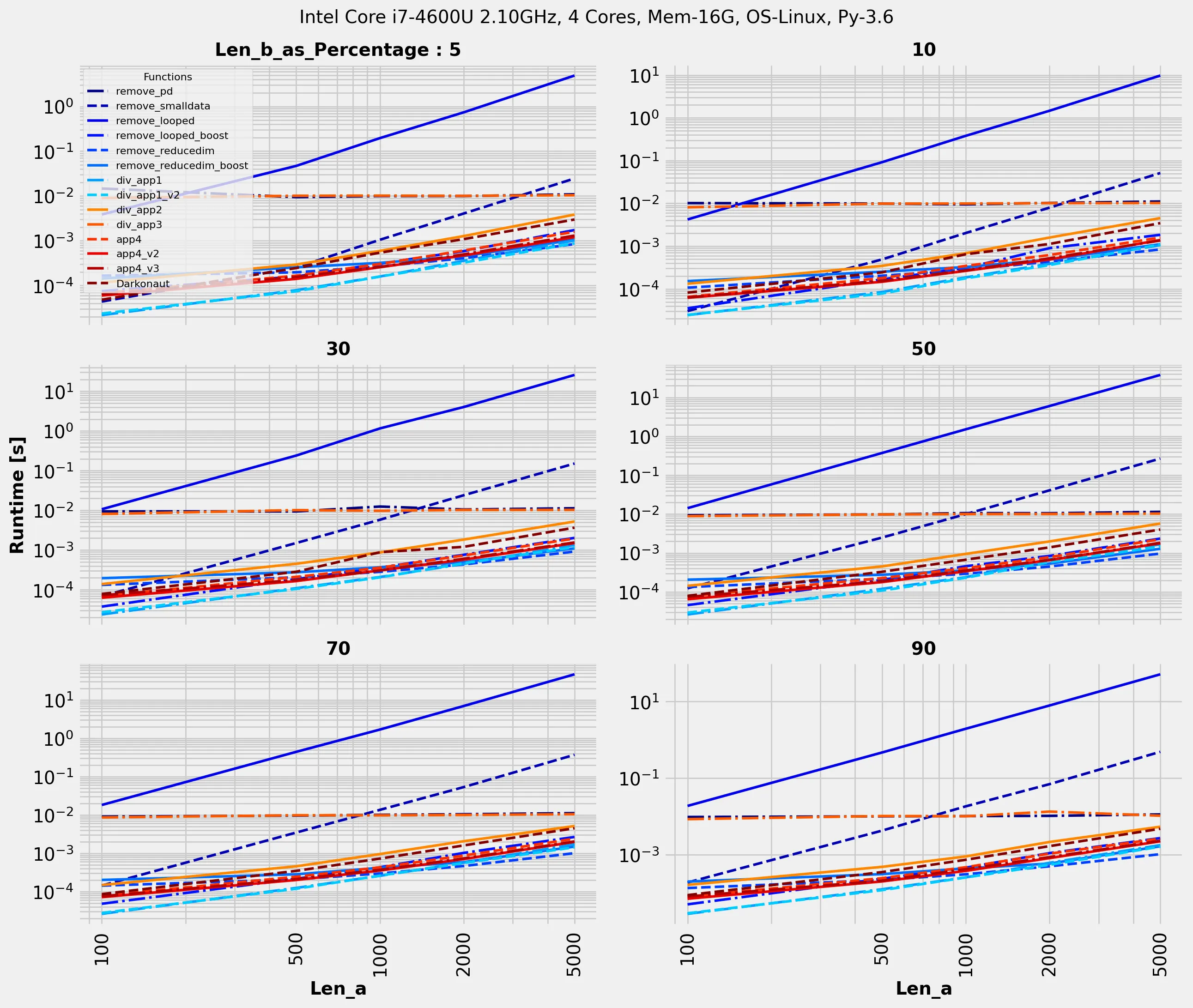
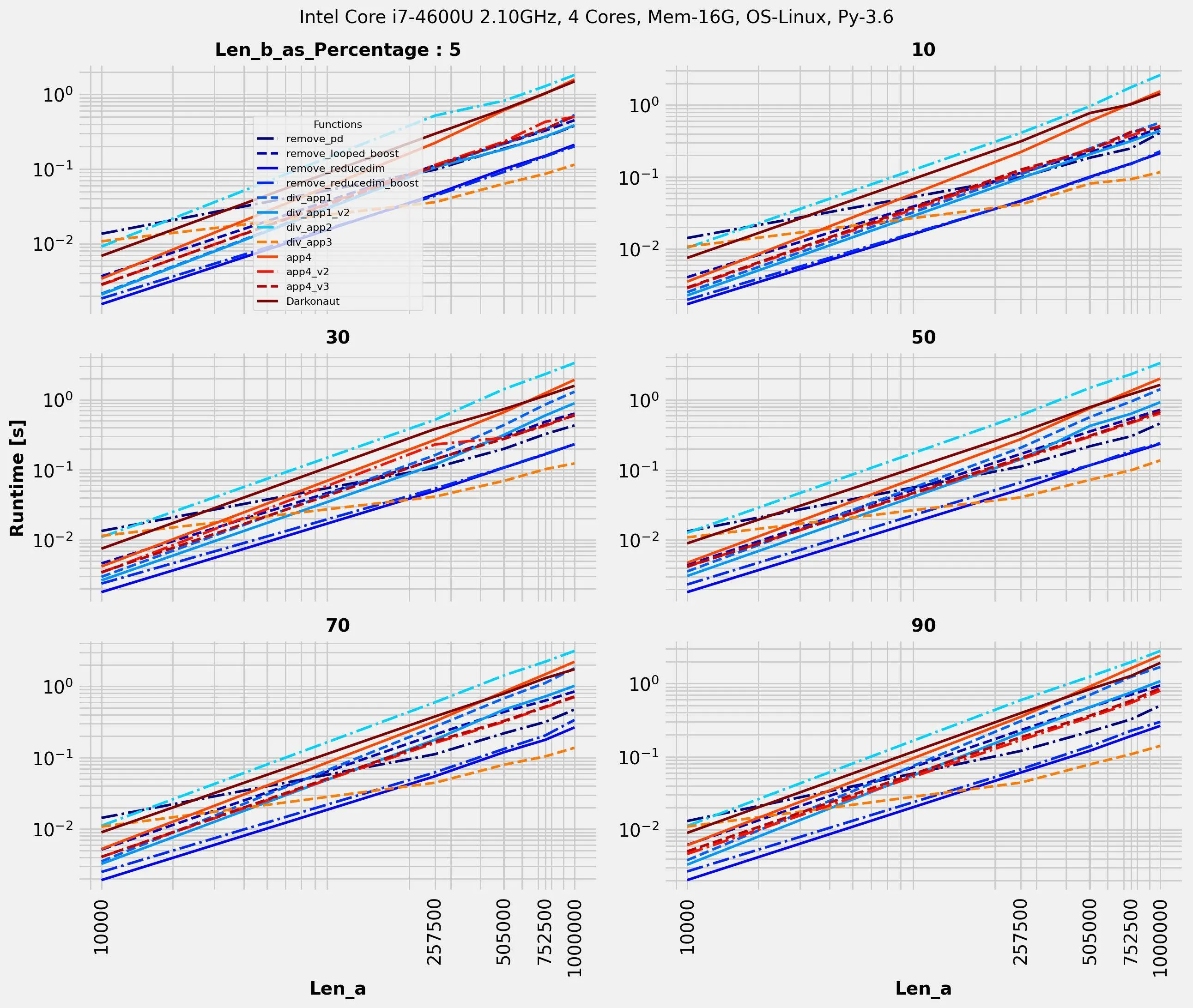
最快的方法是降维,但通常需要对列的范围有相当严格的限制。这里是我的 perfplot:
import pandas as pd
import numexpr as ne
import perfplot
from time import time
def remove_pd(data):
a,b = data
dfa, dfb = pd.DataFrame(a), pd.DataFrame(b)
return dfa.merge(dfb, how='left', indicator=True)\
.query('_merge == "left_only"').drop(columns='_merge').values
def remove_smalldata(data):
a,b = data
return a[(a[None,:,:] != b[:,None,:]).any(-1).all(0)]
'''def remove_nploop(data):
a, b = data
for arr in b:
a = a[np.all(~np.equal(a, arr), axis=1)]
return a'''
def remove_looped(data):
a, b = data
to_remain = [True]*len(a)
ind = 0
for vec_a in a:
for vec_b in b:
if np.array_equal(vec_a, vec_b):
to_remain[ind] = False
break
ind += 1
return a[to_remain]
def remove_looped_boost(data):
a, b = data
to_remain = [True]*len(a)
a_map = list(map(tuple, a.tolist()))
b_map = set(map(tuple, b.tolist()))
for i in range(len(a)):
to_remain[i] = not(a_map[i] in b_map)
return a[to_remain]
def remove_reducedim(data):
a,b = data
a, b = a.astype(np.int64), b.astype(np.int64) #make sure box is not too small
ma, MA = np.min(a, axis=0), np.max(a, axis=0)
mb, MB = np.min(b, axis=0), np.max(b, axis=0)
m, M = np.min([ma, mb], axis=0), np.max([MA, MB],axis=0)
ravel_a = np.ravel_multi_index((a-m).T, M - m + 1)
ravel_b = np.ravel_multi_index((b-m).T, M - m + 1)
return a[~np.isin(ravel_a, ravel_b)]
def remove_reducedim_boost(data):
a,b = data
a, b = a.astype(np.int64), b.astype(np.int64) #make sure box is not too small
ma, MA = np.min(a, axis=0), np.max(a, axis=0)
mb, MB = np.min(b, axis=0), np.max(b, axis=0)
m1,m2,m3,m4 = np.min([ma, mb], axis=0)
M1,M2,M3,M4 = np.max([MA, MB], axis=0)
s1,s2,s3,s4 = M1-m1+1, M2-m2+1, M3-m3+1, M4-m4+1
a1,a2,a3,a4 = a.T
b1,b2,b3,b4 = b.T
d = {'a1':a1, 'a2':a2, 'a3':a3, 'a4':a4, 'b1':b1, 'b2':b2, 'b3':b3, 'b4':b4,
's1':s1, 's2':s2, 's3':s3, 'm1':m1, 'm2':m2, 'm3':m3, 'm4':m4}
ravel_a = ne.evaluate('(a1-m1)+(a2-m2)*s1+(a3-m3)*s1*s2+(a4-m4)*s1*s2*s3',d)
ravel_b = ne.evaluate('(b1-m1)+(b2-m2)*s1+(b3-m3)*s1*s2+(b4-m4)*s1*s2*s3',d)
return a[~np.isin(ravel_a, ravel_b)]
def setup(x):
a1 = np.random.randint(50000, size=(x,4))
a2 = a1[np.random.randint(x, size=x)]
return a1, a2
def build_args(figure):
kernels = [remove_reducedim, remove_reducedim_boost, remove_pd, remove_looped, remove_looped_boost, remove_smalldata]
return {'setup': setup,
'kernels': {'A': kernels, 'B': kernels[:3]}[figure],
'n_range': {'A': [2 ** k for k in range(12)], 'B': [2 ** k for k in range(11, 25)]}[figure],
'xlabel': 'Remowing n rows from n rows',
'title' : {'A':'Testing removal of small dataset', 'B':'Testing removal of large dataset'}[figure],
'show_progress': False,
'equality_check': lambda x,y: np.array_equal(x, y)}
t = time()
outs = [perfplot.bench(**build_args(n)) for n in ('A','B')]
fig = plt.figure(figsize=(20, 20))
for i in range(len(outs)):
ax = fig.add_subplot(2, 1, i+1)
ax.grid(True, which="both")
outs[i].plot()
plt.show()
print('Overall testing time:', time()-t)
输出:
Overall testing time: 529.2596168518066