我的目标是识别出在以下日期时间格式中,存在高于某个阈值的本地极大值。我知道有其他相关的响应处理使用numpy和scipy技术来查找局部最大值和最小值,但据我所知,没有一个响应涉及到一个阈值级别。
我有一个pandas.Series,表示为df_1,它存储了给定时间的整数值:
然而,我想要生成这些最大值发生的时间数组,而不是使用
接下来,我还打算通过仅选择高于某个阈值的最大值来优化这个时间列表,即其斜率高于某个限制。 这将使我避免获取每个本地最大值,而是识别最重要的“峰值”。 有人有关于如何做到这一点的建议吗?
我有一个pandas.Series,表示为df_1,它存储了给定时间的整数值:
t_min
2015-12-26 14:45:00 46
2015-12-26 14:46:00 25
2015-12-26 14:47:00 39
2015-12-26 14:48:00 58
2015-12-26 14:49:00 89
2015-12-26 14:50:00 60
2015-12-26 14:51:00 57
2015-12-26 14:52:00 60
2015-12-26 14:53:00 46
2015-12-26 14:54:00 31
2015-12-26 14:55:00 66
2015-12-26 14:56:00 78
2015-12-26 14:57:00 49
2015-12-26 14:58:00 47
2015-12-26 14:59:00 31
2015-12-26 15:00:00 55
2015-12-26 15:01:00 19
2015-12-26 15:02:00 10
2015-12-26 15:03:00 31
2015-12-26 15:04:00 36
2015-12-26 15:05:00 61
2015-12-26 15:06:00 29
2015-12-26 15:07:00 32
2015-12-26 15:08:00 49
2015-12-26 15:09:00 35
2015-12-26 15:10:00 17
2015-12-26 15:11:00 22
我使用以下方法来推断数组索引,在另一个回答中找到本地极大值:
x = np.array(df_1, dtype=np.float)
# for local maxima
print argrelextrema(x, np.greater)
然而,我想要生成这些最大值发生的时间数组,而不是使用
x[argrelextrema(x, np.greater)[0]]得到的整数(现在转换为浮点数)索引值。 有什么办法可以获得所需时间的数组吗?接下来,我还打算通过仅选择高于某个阈值的最大值来优化这个时间列表,即其斜率高于某个限制。 这将使我避免获取每个本地最大值,而是识别最重要的“峰值”。 有人有关于如何做到这一点的建议吗?
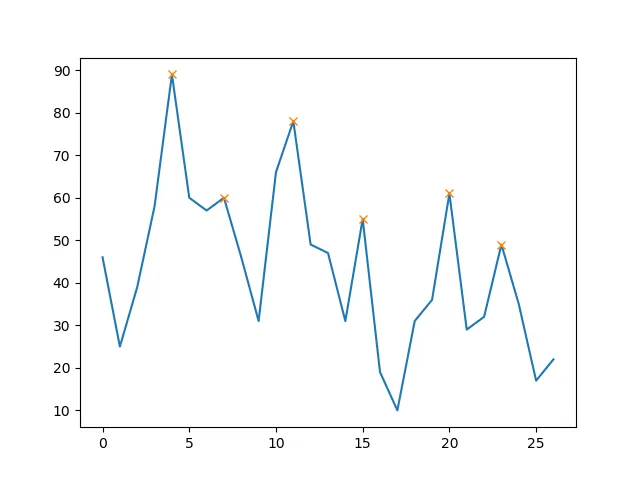
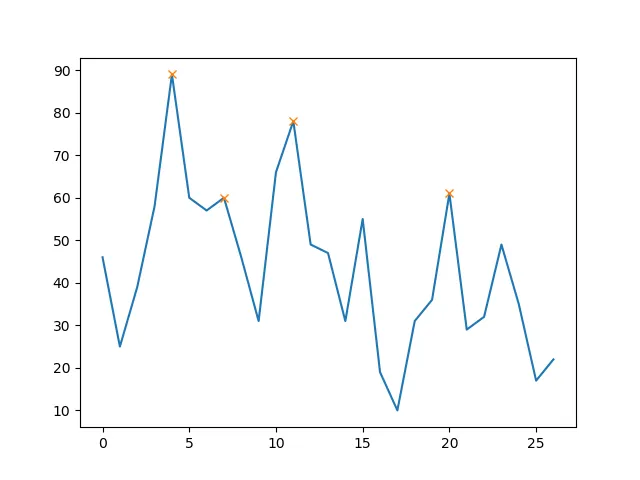
scipy.signal中的argrelextrema,如下所示:x = np.array(df_1, dtype=np.float) # for local maxima print argrelextrema(x, np.greater)这给了我数组[4, 7, 11, 15, 20, 23],但是我想返回这些索引所指向的原始数据帧的时间。您有任何想法如何做到这一点吗?先感谢您。 - DK99d),并对其进行索引:[d[j] for j in indices]。 - Roland Smith