我的数据标签是一个(N行1列)的向量。标签值为0表示负样本,1表示正样本(因此,这是一个二分类问题)。我使用sklearn中的
.fit函数,在我的训练集上拟合了一个随机森林。要计算测试集的AUC,我使用metrics.roc_auc_score(test_labels, probabilities)。我使用predict_proba(my_test_set)获得概率。然而,predict_proba(my_test_set)返回一个(N_test,2)的矩阵。我看到很多人使用这个返回矩阵的第二列(predict_proba(my_test_set)[:,1]),并将其提供给metrics.roc_auc_score来计算AUC,但为什么是第二列?为什么不是第一列(predict_proba(my_test_set)[:,0])?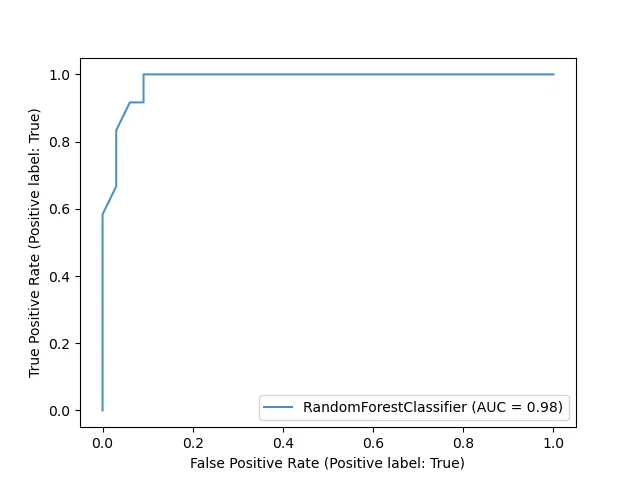
predict_proba(my_test_set)[:,0])中是什么?负类的概率吗?这就是为什么predict_proba(my_test_set)[i,0] + predict_proba(my_test_set)[i,1] = 1吗?谢谢! - khemedi