我正在尝试使用正在创建的列的偏移值来创建一个新的 Pandas DataFrame 列。
我目前唯一能够实现这个功能的方式是通过遍历数据,这会导致代码运行缓慢并且成为瓶颈。
import pandas as pd
df = pd.DataFrame([1,6,2,8], columns=['a'])
df.at[0, 'b'] = 5
for i in range(1, len(df)):
df.loc[i, ('b')] = (df.a[i-1] + df.b[i-1]) /2
我尝试使用 shift 但没有成功。它会填充第一行的值,而其他行则为 NaN。我猜测这种方法不能实时读取新创建的值。
df.loc[1:, ('b')] = (df.a.shift() + df.b.shift()) /2
更新
我能够通过在迭代中使用df.at而不是df.loc来显着缩短时间。
def with_df_loc(df):
for i in range(1, len(df)):
df.loc[i, ('b')] = (df.a[i-1] + df.b[i-1]) /2
return df
def with_df_at(df):
for i in range(1, len(df)):
df.at[i, 'b'] = (df.a[i-1] + df.b[i-1]) /2
return df
%timeit with_df_loc(df)
183 ms ± 75.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit with_df_at(df)
19.4 ms ± 2.74 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
这个时间是基于一个包含150行的更大数据集。考虑到df.rolling(20).mean()需要约3毫秒,我认为这可能是我能做到的最好结果。
感谢您的回答,如果我需要进一步优化,我会研究Asish M建议中的numba。
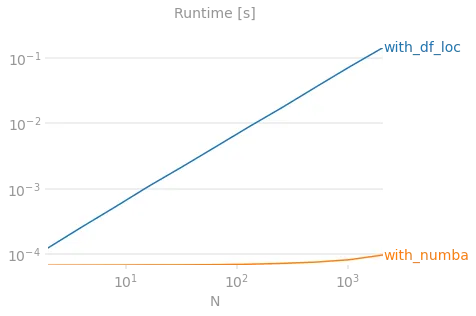
numba来加速循环。 - Asish M.df.at而不是df.loc来加快速度,但如果您知道其他方法,我很乐意听取。始终寻找改进代码的方法。 - JDavda