您好,我正在尝试找到一种向量化(或更有效的)的解决方案来解决迭代问题,但我找到的唯一解决方案需要对带有多个循环的DataFrame进行逐行迭代。由于实际数据文件非常庞大,因此我的当前解决方案实际上是不可行的。如果您想查看,我在最后附上了行分析器输出。实际问题非常复杂,因此我将尝试通过一个简单的例子来解释它(我花了相当长的时间来简化它:):
假设我们有一个机场,有两条并排的着陆跑道。每架飞机都会降落(到达时间),在其中一条着陆跑道上滑行一段时间,然后起飞(离开时间)。所有信息都存储在一个 Pandas DataFrame 中,并按到达时间排序,如下所示(有关测试的更大数据集,请参见 EDIT2):
PLANE STRIP ARRIVAL DEPARTURE
0 1 85.00 86.00
1 1 87.87 92.76
2 2 88.34 89.72
3 1 88.92 90.88
4 2 90.03 92.77
5 2 90.27 91.95
6 2 92.42 93.58
7 2 94.42 95.58
寻找两个问题的解决方案:
1. 建立一个事件列表,其中在同一条线上同时存在多架飞机。不包括事件的子集(例如,如果有一个有效的[3,4,5]情况,则不显示[3,4])。该列表应存储实际DataFrame行的索引。参见函数findSingleEvents()的解决方案(运行时间约为5毫秒)。
2. 建立一个事件列表,在每条线上至少有一架飞机。不计算事件的子集,仅记录具有最大数量飞机的事件。(例如,如果有一个[3,4,5]情况,则不显示[3,4])。不计算完全发生在单个线路上的事件。该列表应存储实际DataFrame行的索引。参见函数findMultiEvents()的解决方案(运行时间约为15毫秒)。
代码示例:
import numpy as np
import pandas as pd
import itertools
from __future__ import division
data = [{'PLANE':0, 'STRIP':1, 'ARRIVAL':85.00, 'DEPARTURE':86.00},
{'PLANE':1, 'STRIP':1, 'ARRIVAL':87.87, 'DEPARTURE':92.76},
{'PLANE':2, 'STRIP':2, 'ARRIVAL':88.34, 'DEPARTURE':89.72},
{'PLANE':3, 'STRIP':1, 'ARRIVAL':88.92, 'DEPARTURE':90.88},
{'PLANE':4, 'STRIP':2, 'ARRIVAL':90.03, 'DEPARTURE':92.77},
{'PLANE':5, 'STRIP':2, 'ARRIVAL':90.27, 'DEPARTURE':91.95},
{'PLANE':6, 'STRIP':2, 'ARRIVAL':92.42, 'DEPARTURE':93.58},
{'PLANE':7, 'STRIP':2, 'ARRIVAL':94.42, 'DEPARTURE':95.58}]
df = pd.DataFrame(data, columns = ['PLANE','STRIP','ARRIVAL','DEPARTURE'])
def findSingleEvents(df):
events = []
for row in df.itertuples():
#Create temporary dataframe for each main iteration
dfTemp = df[(row.DEPARTURE>df.ARRIVAL) & (row.ARRIVAL<df.DEPARTURE)]
if len(dfTemp)>1:
#convert index values to integers from long
current_event = [int(v) for v in dfTemp.index.tolist()]
#loop backwards to remove elements that do not comply
for i in reversed(current_event):
if (dfTemp.loc[i].ARRIVAL > dfTemp.DEPARTURE).any():
current_event.remove(i)
events.append(current_event)
#remove duplicate events
events = map(list, set(map(tuple, events)))
return events
def findMultiEvents(df):
events = []
for row in df.itertuples():
#Create temporary dataframe for each main iteration
dfTemp = df[(row.DEPARTURE>df.ARRIVAL) & (row.ARRIVAL<df.DEPARTURE)]
if len(dfTemp)>1:
#convert index values to integers from long
current_event = [int(v) for v in dfTemp.index.tolist()]
#loop backwards to remove elements that do not comply
for i in reversed(current_event):
if (dfTemp.loc[i].ARRIVAL > dfTemp.DEPARTURE).any():
current_event.remove(i)
#remove elements only on 1 strip
if len(df.iloc[current_event].STRIP.unique()) > 1:
events.append(current_event)
#remove duplicate events
events = map(list, set(map(tuple, events)))
return events
print findSingleEvents(df[df.STRIP==1])
print findSingleEvents(df[df.STRIP==2])
print findMultiEvents(df)
验证输出:
[[1, 3]]
[[4, 5], [4, 6]]
[[1, 3, 4, 5], [1, 4, 6], [1, 2, 3]]
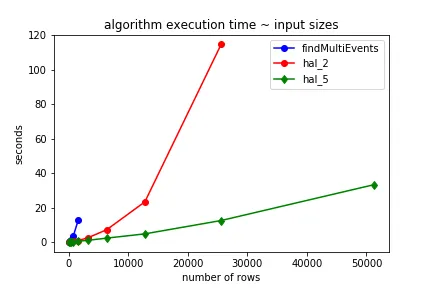
显然,这些解决方案既不高效也不优雅。对于我拥有的大型数据帧,运行这个可能需要数小时。我思考了向量化方法很长一段时间,但没有想到什么可靠的方法。欢迎任何指针/帮助!我也可以接受基于Numpy/Cython/Numba的方法。
谢谢!
PS:如果你想知道我将如何处理这些列表:我将为每个EVENT分配一个EVENT编号,并构建一个单独的数据库来合并上述数据和EVENT编号作为单独的列,以便用于其他用途。对于Case 1,它看起来会像这样:
EVENT PLANE STRIP ARRIVAL DEPARTURE
0 4 2 90.03 92.77
0 5 2 90.27 91.95
1 5 2 90.27 91.95
1 6 2 92.42 95.58
编辑: 修正了代码和测试数据集。
编辑2: 使用以下代码生成一个包含1000行(或更多)的DataFrame,用于测试目的。(根据@ImportanceOfBeingErnest的建议)
import random
import pandas as pd
import numpy as np
data = []
for i in range(1000):
arrival = random.uniform(0,1000)
departure = arrival + random.uniform(2.0, 10.0)
data.append({'PLANE':i, 'STRIP':random.randint(1, 2),'ARRIVAL':arrival,'DEPARTURE':departure})
df = pd.DataFrame(data, columns = ['PLANE','STRIP','ARRIVAL','DEPARTURE'])
df = df.sort_values(by=['ARRIVAL'])
df = df.reset_index(drop=True)
df.PLANE = df.index
EDIT3:
已修改的被接受答案。原先被接受的答案不能删除事件的子集。修改后的版本满足规则“(例如,如果存在有效的[3,4,5]情况,则不显示[3,4])”
def maximal_subsets_modified(sets):
sets.sort()
maximal_sets = []
s0 = frozenset()
for s in sets:
if not (s > s0) and len(s0) > 1:
not_in_list = True
for x in maximal_sets:
if set(x).issubset(set(s0)):
maximal_sets.remove(x)
if set(s0).issubset(set(x)):
not_in_list = False
if not_in_list:
maximal_sets.append(list(s0))
s0 = s
if len(s0) > 1:
not_in_list = True
for x in maximal_sets:
if set(x).issubset(set(s0)):
maximal_sets.remove(x)
if set(s0).issubset(set(x)):
not_in_list = False
if not_in_list:
maximal_sets.append(list(s0))
return maximal_sets
def maximal_subsets_2_modified(sets, d):
sets.sort()
maximal_sets = []
s0 = frozenset()
for s in sets:
if not (s > s0) and len(s0) > 1 and d.loc[list(s0), 'STRIP'].nunique() == 2:
not_in_list = True
for x in maximal_sets:
if set(x).issubset(set(s0)):
maximal_sets.remove(x)
if set(s0).issubset(set(x)):
not_in_list = False
if not_in_list:
maximal_sets.append(list(s0))
s0 = s
if len(s0) > 1 and d.loc[list(s), 'STRIP'].nunique() == 2:
not_in_list = True
for x in maximal_sets:
if set(x).issubset(set(s0)):
maximal_sets.remove(x)
if set(s0).issubset(set(x)):
not_in_list = False
if not_in_list:
maximal_sets.append(list(s0))
return maximal_sets
# single
def hal_3_modified(d):
sets = np.apply_along_axis(
lambda x: frozenset(d.PLANE.values[(d.PLANE.values <= x[0]) & (d.DEPARTURE.values > x[2])]),
1, d.values
)
return maximal_subsets_modified(sets)
# multi
def hal_5_modified(d):
sets = np.apply_along_axis(
lambda x: frozenset(d.PLANE.values[(d.PLANE.values <= x[0]) & (d.DEPARTURE.values > x[2])]),
1, d.values
)
return maximal_subsets_2_modified(sets, d)
itertuples()和iterrows(),但我无法弄清如何实现所需的嵌套循环。 - marillioniloc的迭代方式本来就没有正确设置。我需要先解决这个问题。 - marillion