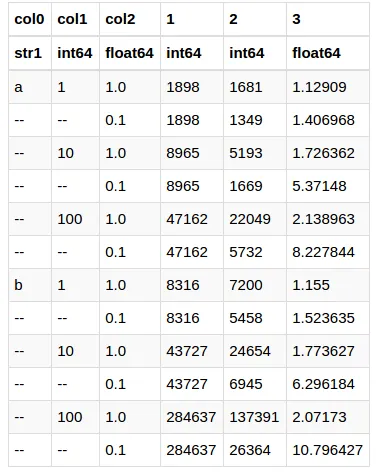
有没有什么简单的方法可以将由DataFrame方法to_latex()生成的Latex表格读回到另一个DataFrame中?特别是,我正在寻找能够处理Multiindex的内容。例如,如果我们有以下文件“test.out”:
\begin{tabular}{llllrrr}
\toprule
& & & 1 & 2 & 3 \\
\midrule
a & 1 & 1.0 & 1898 & 1681 & 1.129090 \\
& & 0.1 & 1898 & 1349 & 1.406968 \\
& 10 & 1.0 & 8965 & 5193 & 1.726362 \\
& & 0.1 & 8965 & 1669 & 5.371480 \\
& 100 & 1.0 & 47162 & 22049 & 2.138963 \\
& & 0.1 & 47162 & 5732 & 8.227844 \\
b & 1 & 1.0 & 8316 & 7200 & 1.155000 \\
& & 0.1 & 8316 & 5458 & 1.523635 \\
& 10 & 1.0 & 43727 & 24654 & 1.773627 \\
& & 0.1 & 43727 & 6945 & 6.296184 \\
& 100 & 1.0 & 284637 & 137391 & 2.071730 \\
& & 0.1 & 284637 & 26364 & 10.796427 \\
\bottomrule
\end{tabular}
我的第一次尝试是将其读作
df = pd.read_csv('test.out',
sep='&',
header=None,
index_col=(0,1,2),
skiprows=4,
skipfooter=3,
engine='python')
由于read_csv()将空字段视为多级索引的新层级,因此导致其无法正常工作:
In [4]: df.index
Out[4]:
MultiIndex(levels=[[u' ', u'a ', u'b '], [u' ', u' 1
', u' 10 ', u' 100 '], [0.1, 1.0]],
labels=[[1, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0], [1, 0, 2, 0, 3, 0, 1,
0, 2, 0, 3, 0], [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0]],
names=[0, 1, 2])
有没有什么方法可以实现这个?