请问有人能帮忙将以下XML文件转换为Pandas数据框:
<?xml version="1.0" encoding="UTF-8" ?>
<root>
<bathrooms type="dict">
<n35237 type="number">1.0</n35237>
<n32238 type="number">3.0</n32238>
<n44699 type="number">nan</n44699>
</bathrooms>
<price type="dict">
<n35237 type="number">7020000.0</n35237>
<n32238 type="number">10000000.0</n32238>
<n44699 type="number">4128000.0</n44699>
</price>
<property_id type="dict">
<n35237 type="number">35237.0</n35237>
<n32238 type="number">32238.0</n32238>
<n44699 type="number">44699.0</n44699>
</property_id>
</root>它应该看起来像这样--
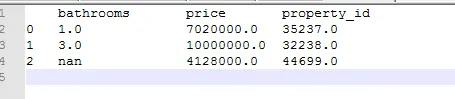{kind=link}
这是我编写的代码:
import pandas as pd
import xml.etree.ElementTree as ET
tree = ET.parse('real_state.xml')
root = tree.getroot()
dfcols = ['property_id', 'price', 'bathrooms']
df_xml = pd.DataFrame(columns=dfcols)
for node in root:
property_id = node.attrib.get('property_id')
price = node.attrib.get('price')
bathrooms = node.attrib.get('bathrooms')
df_xml = df_xml.append(
pd.Series([property_id, price, bathrooms], index=dfcols),
ignore_index=True)
print(df_xml)
我到处都得到了None,而不是实际的值。请问有人能告诉我如何修复它吗?谢谢!