在ggplot2调用中,是否可能过滤掉数据子集中观测次数较少的部分?
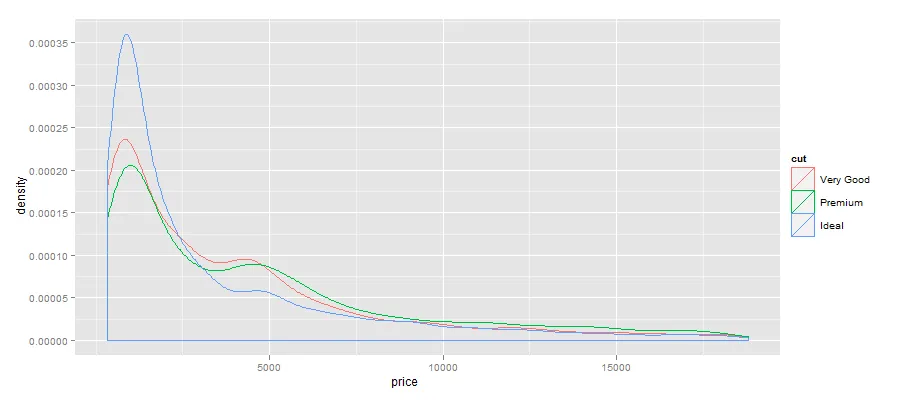
例如,考虑以下图表:
例如,考虑以下图表:
qplot(price,data=diamonds,geom="density",colour=cut)
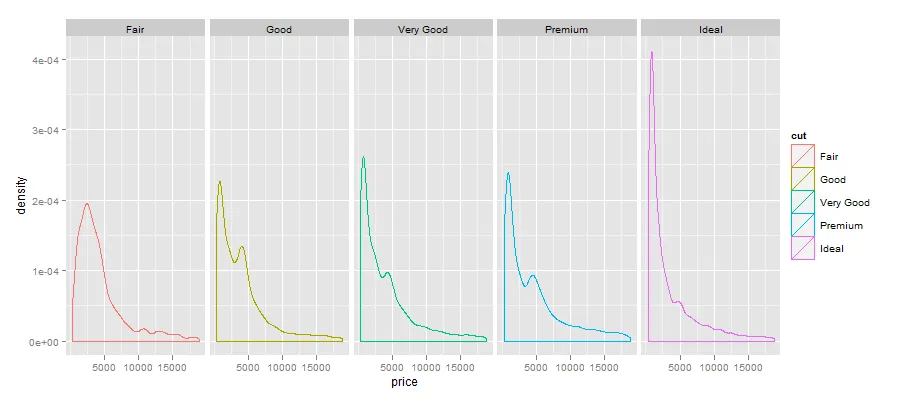
这个图表有点繁琐,我想排除观测次数较少的cut值,即:> xtabs(~cut,diamonds)
cut
Fair Good Very Good Premium Ideal
1610 4906 12082 13791 21551
切割因子的“优”和“良”质量。
我希望有一个能够适应任意数据集的解决方案,如果可能的话,不仅可以通过观测值的阈值数量进行选择,还可以选择前三个观测值。
..nobservations..变量可以访问,或者使用stat_sum进行一些操作,但这种子集方式更加明确。 - James