我有一段代码像这样
imdb_dir = '/home/yan/PycharmProjects/NLTK_ML/aclImdb'
train_dir = os.path.join(imdb_dir, 'train')
labels = []
texts = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in tqdm(os.listdir(dir_name)):
if fname[-4:] == '.txt':
# Read the text file and put it in the list
f = open(os.path.join(dir_name, fname))
texts.append(f.read())
f.close()
# Attach the corresponding label
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
max_words = 10000
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
maxlen = 100 # Make all sequences 100 words long
data = pad_sequences(sequences, maxlen=maxlen)
labels = np.asarray(labels)
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
training_samples = 20000
validation_samples = 5000
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples: training_samples + validation_samples]
y_val = labels[training_samples: training_samples + validation_samples]
glove_dir = '/home/yan/PycharmProjects/NLTK_ML' # This is the folder with the dataset
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'))
for line in tqdm(f):
values = line.split()
word = values[0] # The first value is the word, the rest are the values of the embedding
embedding = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = embedding
f.close()
all_embs = np.stack(embeddings_index.values())
emb_mean = all_embs.mean() # Calculate mean
emb_std = all_embs.std() # Calculate standard deviation
emb_mean,emb_std
embedding_dim = 100
word_index = tokenizer.word_index
nb_words = min(max_words, len(word_index))
embedding_matrix = np.random.normal(emb_mean, emb_std, (nb_words, embedding_dim))
for word, i in word_index.items():
if i >= max_words:
continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen, weights = [embedding_matrix], trainable = False))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_data=(x_val, y_val))
def getPositivity(my_text):
seq = tokenizer.texts_to_sequences([my_text])
seq = pad_sequences(seq, maxlen=maxlen)
prediction = model.predict(seq)
return prediction
df_ticker['prediction'] = df_ticker['text'].apply(lambda text:getPositivity(text))
# print(df_ticker)
df_ticker.to_csv('NLP_ML.csv', index=False)
这给了我[[0.45654]]。
我有一个数据框。
dt id text compare timestamp
3 2021-04-12 03:17:37+00:00 gu7tiax riot 60$ call 1 2021-04-12
4 2021-04-12 13:15:04+00:00 gu91gf2 vix 0 2021-04-12
5 2021-04-12 14:22:04+00:00 gu99dqg tsal to the moon 0 2021-04-12
我想把这个函数应用于该列的每一行。 我尝试过如下方式, 但它只输出最后一行,而我想要所有的行。
dt id text timestamp prediction
5 2021-04-12 14:22:04+00:00 gu99dqg tsal to the moon 0 2021-04-12 [[0.29380253]]
我认为问题出在最后几行代码,那里应用了 getPositivity 函数。我尝试在新的数据框上应用 moview reviews NLTK 。因此,我尝试在整个新数据框上应用机器学习,但它只给我一行,当我想输出所有带有积极得分的行时。
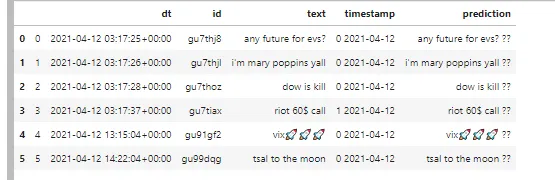
df_ticker['prediction'] = df_ticker['text'].apply(lambda text:getPositivity(text))- prakash sellathurai