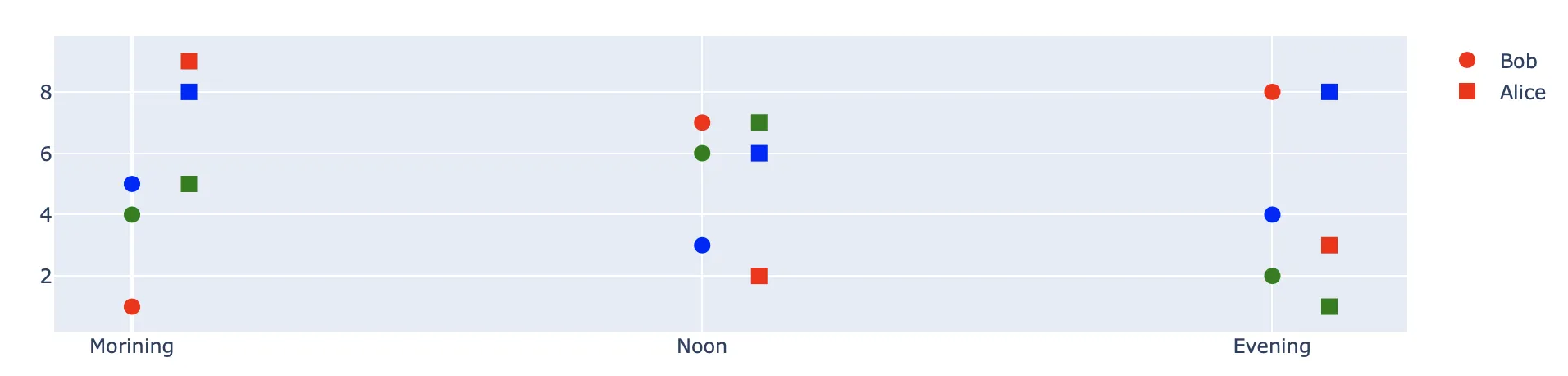
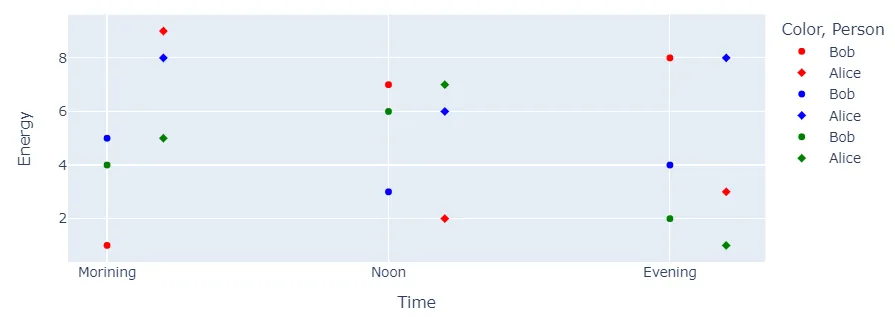
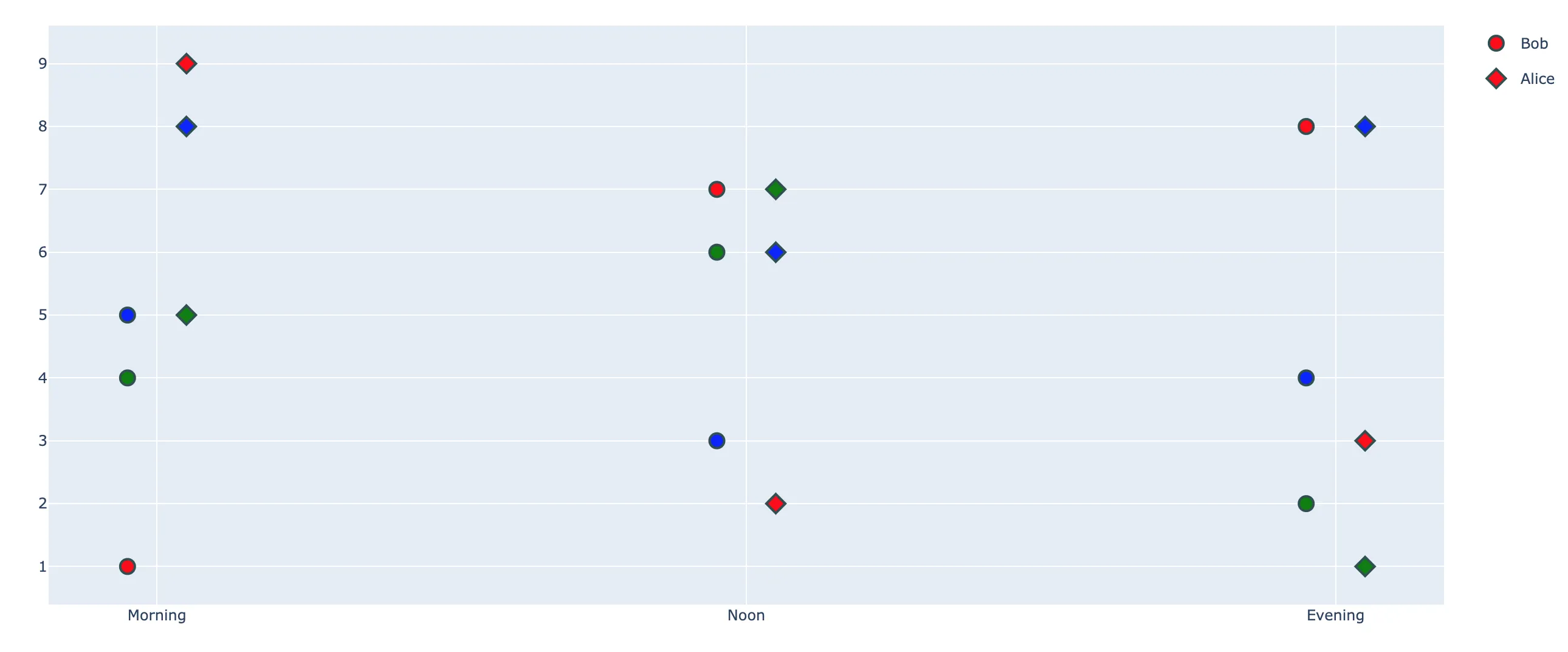
如果您只想使用matplotlib而不需要其他依赖项,这里是一个示例代码。(Pandas操作groupbys等留给您优化)
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.transforms as transforms
from matplotlib.lines import Line2D
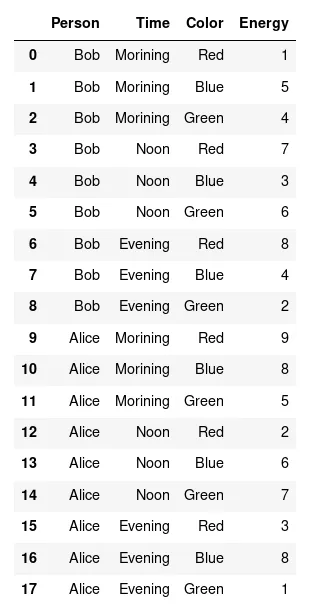
df = pd.DataFrame(
{
'Person': ['Bob'] * 9 + ['Alice'] * 9,
'Time': ['Morning'] * 3
+ ['Noon'] * 3
+ ['Evening'] * 3
+ ['Morning'] * 3
+ ['Noon'] * 3
+ ['Evening'] * 3,
'Color': ['Red', 'Blue', 'Green'] * 6,
'Energy': [1, 5, 4, 7, 3, 6, 8, 4, 2, 9, 8, 5, 2, 6, 7, 3, 8, 1],
}
)
plt.figure()
x = ['Morning', 'Noon', 'Evening']
offset = lambda p: transforms.ScaledTranslation(
p / 72.0, 0, plt.gcf().dpi_scale_trans
)
trans = plt.gca().transData
start_offset = -len(df['Person'].unique()) // 2
markers = ['o', '^']
custom_legend = []
df = df.groupby(['Person', 'Time', 'Color'])['Energy'].sum().reset_index()
df = df.set_index('Time')
for i, [person, pgroup] in enumerate(df.groupby('Person')):
pts = (i + start_offset) * 10
marker = markers[i]
transform = trans + offset(pts)
custom_legend.append(
Line2D(
[0],
[0],
color='w',
markerfacecolor='black',
marker=marker,
markersize=10,
label=person,
)
)
for color, cgroup in pgroup.groupby('Color'):
mornings = cgroup.loc[cgroup.index == 'Morning', 'Energy'].values[0]
noons = cgroup.loc[cgroup.index == 'Noon', 'Energy'].values[0]
evenings = cgroup.loc[cgroup.index == 'Evening', 'Energy'].values[0]
if pts == 0:
plt.scatter(
x,
[mornings, noons, evenings],
c=color.lower(),
s=25,
marker=marker,
)
else:
plt.scatter(
x,
[mornings, noons, evenings],
c=color.lower(),
s=25,
marker=marker,
transform=transform,
)
plt.ylabel('Energy')
plt.xlabel('Time')
plt.legend(handles=custom_legend)
plt.margins(x=0.5)
plt.show()
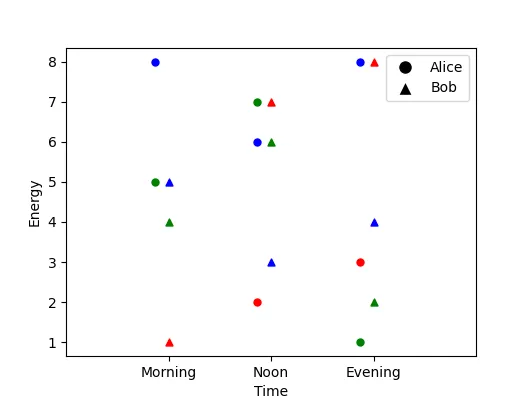
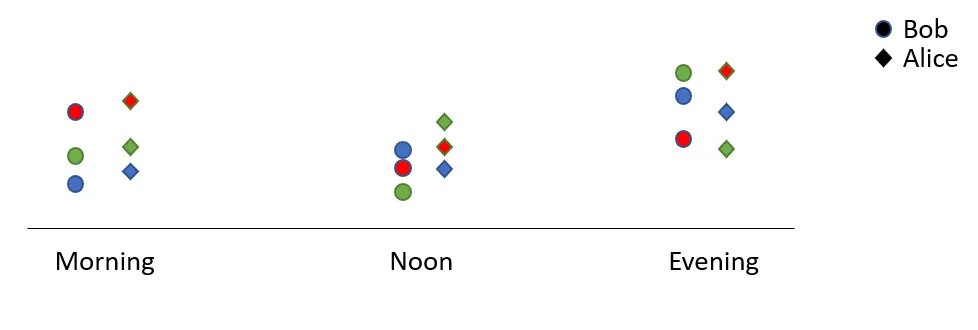 (请忽略粗糙的绘图)
(请忽略粗糙的绘图)