我想在我的Pandas数据帧中添加一个累计总和列,以便:
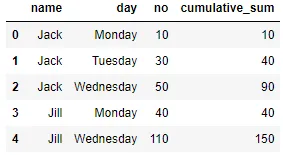
| name | day | no | cumulative_sum |
|---|---|---|---|
| Jack | Monday | 10 | 10 |
| Jack | Tuesday | 20 | 30 |
| Jack | Tuesday | 10 | 40 |
| Jack | Wednesday | 50 | 90 |
| Jill | Monday | 40 | 40 |
| Jill | Wednesday | 110 | 150 |
变成:
Jack | Monday | 10 | 10
Jack | Tuesday | 30 | 40
Jack | Wednesday | 50 | 90
Jill | Monday | 40 | 40
Jill | Wednesday | 110 | 150
我尝试了各种df.groupby和df.agg(lambda x: cumsum(x))的组合,但都没有成功。