我有以下数据框:
df = pd.DataFrame({"values":[1,5,7,3,0,9,8,8,7,5,8,1,0,0,0,0,2,5],"signal":['L_exit',None,None,'R_entry','R_exit',None,'L_entry','L_exit',None,'R_entry','R_exit','R_entry','R_exit','L_entry','L_exit','L_entry','R_exit',None]})
df
values signal
0 1 L_exit
1 5 None
2 7 None
3 3 R_entry
4 0 R_exit
5 9 None
6 8 L_entry
7 8 L_exit
8 7 None
9 5 R_entry
10 8 R_exit
11 1 R_entry
12 0 R_exit
13 0 L_entry
14 0 L_exit
15 0 L_entry
16 2 R_exit
17 5 None
我的目标是添加一个类似于这样的tx列:
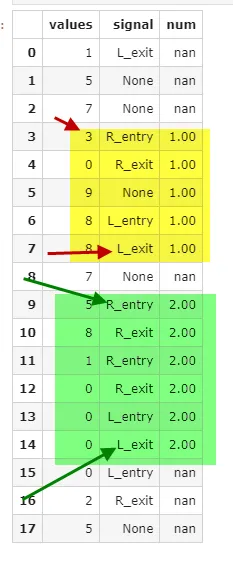
values signal num
0 1 L_exit nan
1 5 None nan
2 7 None nan
3 3 R_entry 1.00
4 0 R_exit 1.00
5 9 None 1.00
6 8 L_entry 1.00
7 8 L_exit 1.00
8 7 None nan
9 5 R_entry 2.00
10 8 R_exit 2.00
11 1 R_entry 2.00
12 0 R_exit 2.00
13 0 L_entry 2.00
14 0 L_exit 2.00
15 0 L_entry nan
16 2 R_exit nan
17 5 None nan
业务逻辑:当有 R_entry 信号时,我们将交易分组直到出现 L_exit 信号(如果有另一个 R_entry 信号,则忽略它)。
可视化
我尝试了什么?
g = ( df['signal'].eq('R_entry') | df_tx['signal'].eq('L_exit') ).cumsum()
df['tx'] = g.where(df['signal'].eq('R_entry')).groupby(g).ffill()
问题在于每次出现'R_entry'时它都会增加。