我需要编写一个程序,从命令行读取文件并将其转换为ASCII艺术格式。我正在使用PPM格式,这里有一个链接指向该项目:项目链接。
以下是我目前的进展:
import sys
def main(filename):
image = open(filename)
#reads through the first three lines
color = image.readline().splitlines()
size_width, size_height = image.readline().split()
max_color = image.readline().splitlines()
#reads the body of the file
pixels = image.read().split()
red = 0
green = 0
blue = 0
r_g_b_value = []
#pulls out the values of each tuple and coverts it to its grayscale value
for i in pixels:
if i != "\n" or " ":
if len(i) == 3:
red = int(i[0]) * .3
green = int(i[1]) * .59
blue = int(i[2]) * .11
elif len(i) == 2:
red == int(i[0]) * .3
green == int(i[1]) *.59
blue == 0
elif len(i) == 1:
red == int(i[0]) * .3
green == 0
blue == 0
r_g_b_value = [red + green + blue]
character = []
for j in len(r_g_b_value):
if int(j) <= 16:
character = " "
elif int(j) > 16 and int(j) <= 32:
character = "."
elif int(j) > 32 and int(j) <= 48:
character = ","
elif int(j) > 48 and int(j) <= 64:
charcter = ":"
elif int(j) > 64 and int(j) <= 80:
character = ";"
elif int(j) > 80 and int(j) <= 96:
character = "+"
elif int(j) > 96 and int(j) <= 112:
character = "="
elif int(j) > 112 and int(j) <= 128:
character = "o"
elif int(j) > 128 and int(j) <= 144:
character = "a"
elif int(j) > 144 and int(j) <= 160:
character = "e"
elif int(j) > 160 and int(j) <= 176:
character = "0"
elif int(j) > 176 and int(j) <= 192:
character = "$"
elif int(j) > 192 and int(j) <= 208:
character = "@"
elif int(j) > 208 and int(j) <= 224:
character = "A"
elif int(j) > 224 and int(j) <= 240:
character = "#"
else:
character = "M"
grayscale = character
print(grayscale)
main(sys.argv[1])
我得到了一个错误提示,说 'int' 对象不是可迭代的,有没有简单的方法来解决这个问题,同时如何推荐在保留图片的情况下打印出它。
另外我不确定如何保留图片的宽度和高度。
非常感谢任何帮助。

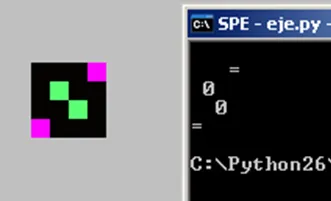 以下是我用于示例的微型ppm文件:
以下是我用于示例的微型ppm文件: