我创建了一个 Spark
当我运行
Dataset[Long] :scala> val ds = spark.range(100000000)
ds: org.apache.spark.sql.Dataset[Long] = [id: bigint]
当我运行
ds.count时,它在4核8GB的机器上用0.2s返回结果。同时,它创建的DAG如下所示:
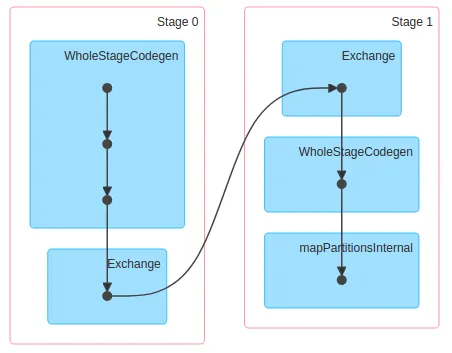
ds.rdd.count时,它在同样的机器上用4s返回结果。但是它创建的DAG如下所示:
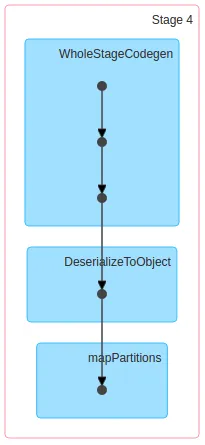
- 为什么
ds.rdd.count只创建一个stage,而ds.count创建了2个stage? - 此外,当
ds.rdd.count只有一个stage时,为什么比有2个stage的ds.count更慢?
ds.rdd.count非常慢,因为需要评估整个数据集(即所有行的所有列),尽管这并不是获取行数所必需的。数据集/数据框架API可以大大优化此查询(另请参见https://dev59.com/OVgQ5IYBdhLWcg3weD2E)。 - Raphael Roth