我知道这个问题的答案很简单,但我已经广泛搜索了论坛,却未能找到解决方案。
我有一个名为
我有一系列的
出于某种原因,我无法弄清如何做到这一点。通常的
以下是相关的数据框:
请注意,"Sex"和"symptoms"变量都是包含缺失值的因子。我尝试了以下方法:
我有一个名为
Data_source 的列,它是我想按照因素分组变量的列。我有一系列的
symptom* 变量,我希望根据 Data_source 计算它们的数量。出于某种原因,我无法弄清如何做到这一点。通常的
group_by 函数似乎不能适当地工作。以下是相关的数据框:
df <- wrapr::build_frame(
"Data_source" , "Sex" , "symptoms_decLOC", "symptoms_nausea_vomitting" |
"1" , "Female", NA_character_ , NA_character_ |
"1" , "Female", NA_character_ , NA_character_ |
"1" , "Female", "No" , NA_character_ |
"1" , "Female", "Yes" , "No" |
"1" , "Female", "Yes" , "No" |
"1" , "Female", "Yes" , "No" |
"1" , "Male" , "Yes" , "No" |
"1" , "Female", "Yes" , "No" |
"2" , "Female", NA_character_ , NA_character_ |
"2" , "Male" , NA_character_ , NA_character_ |
"2" , "Male" , NA_character_ , NA_character_ |
"2" , "Female", "Yes" , "No" |
"2" , "Female", "Yes" , "No" |
"2" , "Male" , NA_character_ , NA_character_ |
"2" , "Male" , NA_character_ , NA_character_ |
"2" , "Male" , NA_character_ , NA_character_ |
"2" , "Female", NA_character_ , NA_character_ |
"2" , "Female", NA_character_ , NA_character_ |
"2" , "Male" , NA_character_ , NA_character_ |
"2" , "Female", NA_character_ , NA_character_ )
请注意,"Sex"和"symptoms"变量都是包含缺失值的因子。我尝试了以下方法:
df %>% na.omit() %>% group_by(Data_source) %>% count("symptoms_decLOC")
以下这种方式不太优秀,因为我必须对每一列都重复操作。理想的方法是使用类似于 lapply(df, count) 的东西,但是这样做不能为每个组提供描述。
编辑
针对下面的问题,我已经添加了预期输出。我在 Excel 中进行了编辑,为了清晰起见着色了group_by。
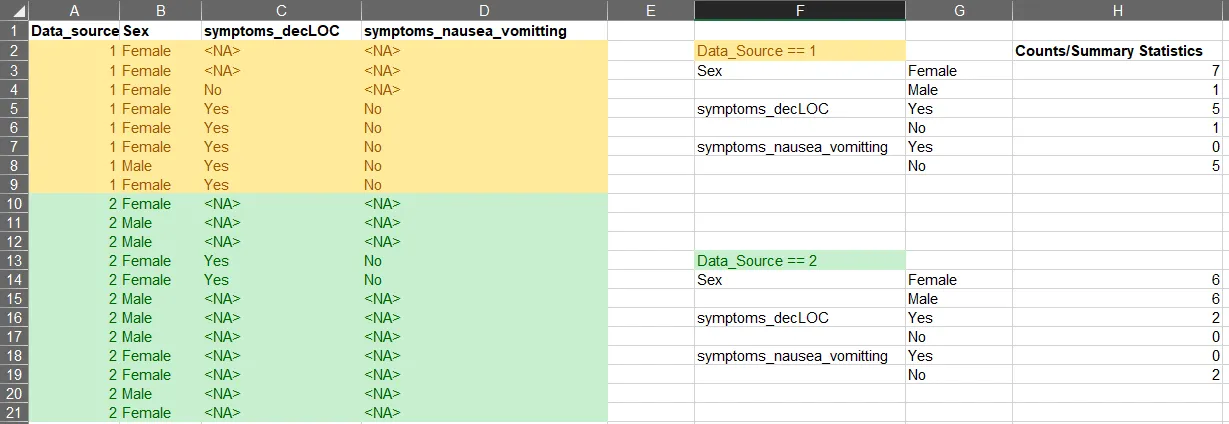
请注意,我正在获取每个可能答案的详细信息。当我使用 dplyr 运行时,以下是输出。
> df %>% na.omit() %>% group_by(Data_source) %>% count("symptoms_decLOC")
# A tibble: 2 x 3
# Groups: Data_source [2]
Data_source `"symptoms_decLOC"` n
<chr> <chr> <int>
1 1 symptoms_decLOC 5
2 2 symptoms_decLOC 2