我有一个数据框,其中
因此,例如,如果这是我的数据框:
所以行0和行3重叠 - 因此它们应该在同一组中,而且行1与行3重叠 - 因此它加入了这个组。
因此,对于这个示例,输出应该是这样的:
我想了很多方向,但是没有想出来(不用丑陋的
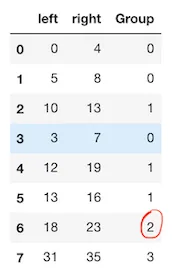
left列是对象最左边的位置,right列是对象最右边的位置。如果它们重叠,或者它们与重叠的对象重叠(递归),我需要对这些对象进行分组。因此,例如,如果这是我的数据框:
left right
0 0 4
1 5 8
2 10 13
3 3 7
4 12 19
5 18 23
6 31 35
所以行0和行3重叠 - 因此它们应该在同一组中,而且行1与行3重叠 - 因此它加入了这个组。
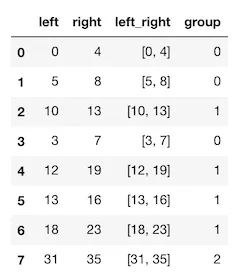
因此,对于这个示例,输出应该是这样的:
left right group
0 0 4 0
1 5 8 0
2 10 13 1
3 3 7 0
4 12 19 1
5 18 23 1
6 31 35 2
我想了很多方向,但是没有想出来(不用丑陋的
for)。任何帮助都将不胜感激!