如果要聚类的数据是点(无论是二维的(x, y)还是三维的(x, y, z)),那么选择聚类方法会相对直观。因为我们可以画出它们并可视化,所以我们会更好地知道哪种聚类方法更适合。
例如,如果我的二维数据集的形状如右上角所示,我会知道K-means在这里可能不是一个明智的选择,而DBSCAN似乎是一个更好的想法。
尽管这些示例提供了一些有关算法的直觉,但这种直觉可能不适用于非常高维的数据。
据我所知,在大多数实际问题中,我们没有这样简单的数据。很可能,我们有高维元组,无法像这样可视化数据。
例如,我希望对一个数据集进行聚类,其中每个数据都表示为一个4-D元组。我无法在坐标系中将其可视化并观察其分布,就像以前那样。因此,在这种情况下,我将无法说DBSCAN优于K-means。
因此,我的问题是:
如何为这种“不可视”高维情况选择合适的聚类方法?
例如,如果我的二维数据集的形状如右上角所示,我会知道K-means在这里可能不是一个明智的选择,而DBSCAN似乎是一个更好的想法。
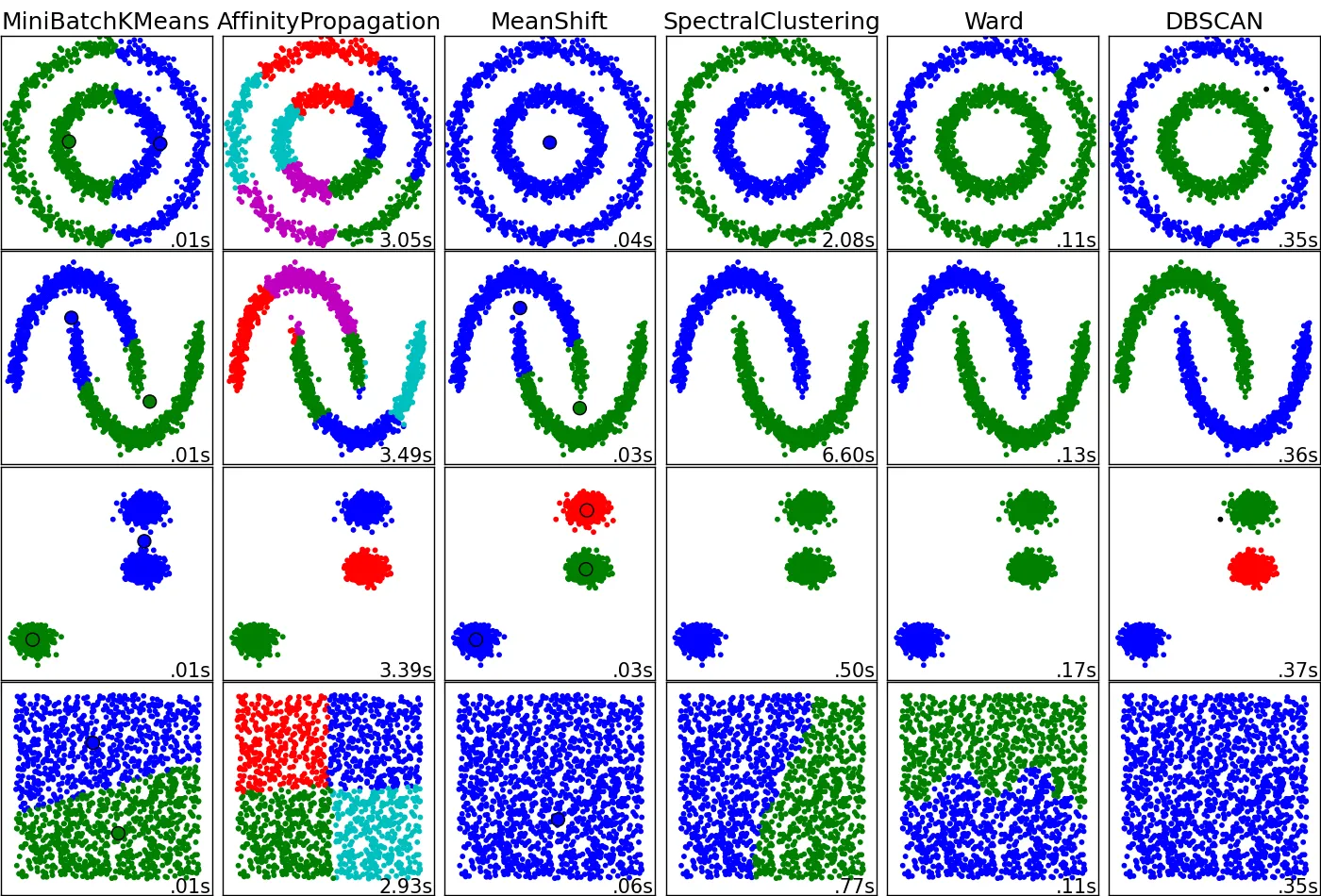
尽管这些示例提供了一些有关算法的直觉,但这种直觉可能不适用于非常高维的数据。
据我所知,在大多数实际问题中,我们没有这样简单的数据。很可能,我们有高维元组,无法像这样可视化数据。
例如,我希望对一个数据集进行聚类,其中每个数据都表示为一个4-D元组。我无法在坐标系中将其可视化并观察其分布,就像以前那样。因此,在这种情况下,我将无法说DBSCAN优于K-means。
因此,我的问题是:
如何为这种“不可视”高维情况选择合适的聚类方法?
{kind=link}
character1?你的意思是你有长度为4的字符串吗?那么你可能不应该直接在该空间中进行聚类,而是先进行一次独热编码。 - Fred Foo