我正在尝试在一些具有高噪声的数据中找到聚类(请参见下面的图)。
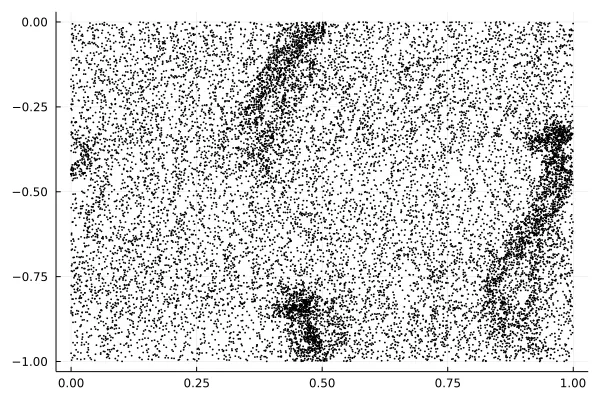
我尝试使用DBSCAN,它有点起作用,但需要手动调整输入参数才能正确地找到聚类。是否有其他适合处理这种数据的好的聚类算法?
一些考虑因素:
我正在使用Julia进行数据处理。
数据在两个方向上都具有周期性边界条件。
聚类数是先验已知的。
我计划以这种方式处理许多数据集,因此它应该运行相对快速,而且不需要太多手动操作。
谢谢!
我正在尝试在一些具有高噪声的数据中找到聚类(请参见下面的图)。
我尝试使用DBSCAN,它有点起作用,但需要手动调整输入参数才能正确地找到聚类。是否有其他适合处理这种数据的好的聚类算法?
一些考虑因素:
我正在使用Julia进行数据处理。
数据在两个方向上都具有周期性边界条件。
聚类数是先验已知的。
我计划以这种方式处理许多数据集,因此它应该运行相对快速,而且不需要太多手动操作。
谢谢!
关于生成/概率模型怎么样?也许它不适合你的情况,但你可以很快地尝试一下:
using Pkg
Pkg.add("BetaML")
using BetaML
m = GMMClusterModel(nClasses=K,mixtures=[FullGaussian() for i in 1:K])
fit!(m,X) # X is a n by d matrix
classes = mode(predict(m))
告诉我!