我一直在研究自组织映射,我理解该算法(我认为),但仍有些东西逃脱了我的理解。
你如何解释训练好的网络?
一旦您使用训练数据进行聚类后,您将如何实际用它来进行分类任务?
我发现所有材料(印刷和数字)都集中在算法的培训上。 我相信我可能会错过一些关键的东西。
问候
我一直在研究自组织映射,我理解该算法(我认为),但仍有些东西逃脱了我的理解。
你如何解释训练好的网络?
一旦您使用训练数据进行聚类后,您将如何实际用它来进行分类任务?
我发现所有材料(印刷和数字)都集中在算法的培训上。 我相信我可能会错过一些关键的东西。
问候
SOM主要是一种减少维度的算法,而不是分类工具。它们用于减少维度,就像PCA和类似方法一样(一旦训练完成,您可以检查哪个神经元被您的输入激活,并使用该神经元的位置作为值),唯一的实际区别是它们能够保留给定输出表示的拓扑结构。
因此,SOM实际上产生的是从您的输入空间X到缩小的空间Y的映射(最常见的是二维点阵,使Y成为二维空间)。要执行实际分类,您应通过这种映射转换数据,并运行一些其他的分类模型(如SVM、神经网络、决策树等)。
换句话说,SOM用于找到数据的其他表示。这种表示对人类来说很容易进一步分析(因为它基本上是二维的,可以绘制),并且非常容易进行任何进一步的分类模型。这是可视化高维数据的好方法,分析“正在发生什么”,一些类别如何几何地分组等等。但是,它们不应与其他神经模型混淆,例如人工神经网络甚至是生长神经气体(这是一个非常相似的概念,但提供直接的数据聚类),因为它们具有不同的目的。
当然,人们可以直接使用SOM进行分类,但这是对原始想法的修改,需要其他数据表示,并且总体而言,与在其上使用其他分类器相比,效果并不那么好。
编辑
有至少几种可视化训练后的SOM的方法:
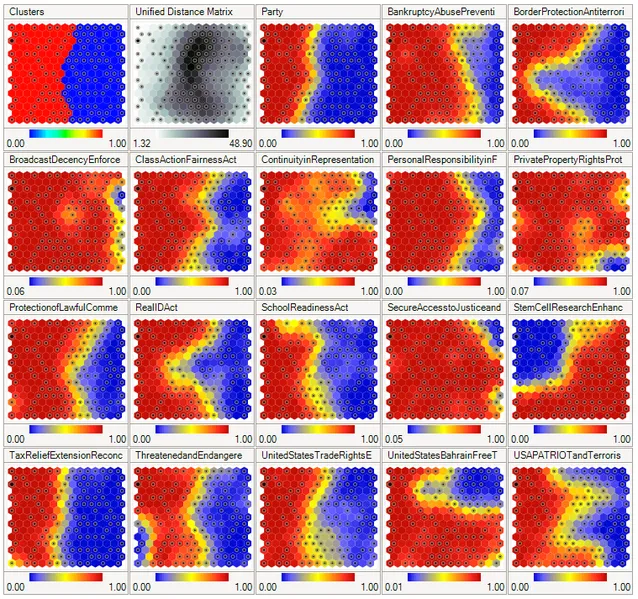
SOM的神经元呈现为输入空间中的点,并连接靠近拓扑的神经元(只有输入空间具有小的维度,如2-3维,才行)SOM 的拓扑结构上展示数据分类 - 如果你的数据被标记为一些数字 {1,..k},我们可以为它们绑定一些 k 种颜色,对于二元情况,让我们考虑 蓝色 和 红色。接下来,对于每个数据点,我们计算它相应的神经元在 SOM 中,并将该标签的颜色添加到神经元中。一旦所有数据都被处理完毕,我们就将 SOM 的神经元绘制出来,每个神经元都有其在拓扑结构中的原始位置,颜色是分配给它的颜色的某种聚合(例如平均值)。如果我们使用一些简单的拓扑结构比如 2D 网格,这种方法会给我们提供一个很好的低维数据表示。在下图中,从第三个子图到最后一个都是这种可视化结果,其中 红色 表示标签 1 ("yes"),蓝色 表示标签 2 ("no")SOM 的地图上绘制来可视化神经元之间的距离(上面可视化结果中的第二个子图)