我过去几个月一直在研究自组织映射(SOM)。但是,我仍然对降维部分的理解有些困惑。您能否建议一种简单的方法来理解SOM在任何真实世界数据集上的实际工作方式(例如来自UCI存储库的数据集)。
1个回答
4
首先,请参考一些之前的相关问题,这将更好地让您了解SOM的降维和可视化属性。 绘制Kohonen地图-理解可视化, 解释自组织映射。
其次,这是一个用于测试SOM属性的简单案例:
- 创建一个具有3个特征的简单数据集,其中有3个不同的簇;
- 对该数据集执行SOM并进行可视化。
我将使用MATLAB编程语言来说明如何做以及从学习过程中可以提取哪些信息。
代码:
% create a dataset with 3 clusters and 3 features
x=[ones(1000,1)*0.5,zeros(1000,1),zeros(1000,1)];
x=[x;[zeros(1000,1),ones(1000,1)*0.5,zeros(1000,1)]];
x=[x;[zeros(1000,1),zeros(1000,1),ones(1000,1)*0.5]];
x=x+rand(3000,3)*0.2;
x=x';
%define a 20x20 SOM through MATLAB "selforgmap" function, and train using the "train"
net = selforgmap([20 20]);
[net,tr] = train(net,x);
%display the number of hits, neighbour distance, and plane maps figure,plotsomplanes(net)
figure,plotsomnd(net)
figure,plotsomhits(net,x)
输出:
在第一张图中,您可以看到将 3000x3 的数据集压缩为 20x20x3 的地图(减少了近10倍)。您还可以看到组件很容易被进一步压缩成三个单独的类别。
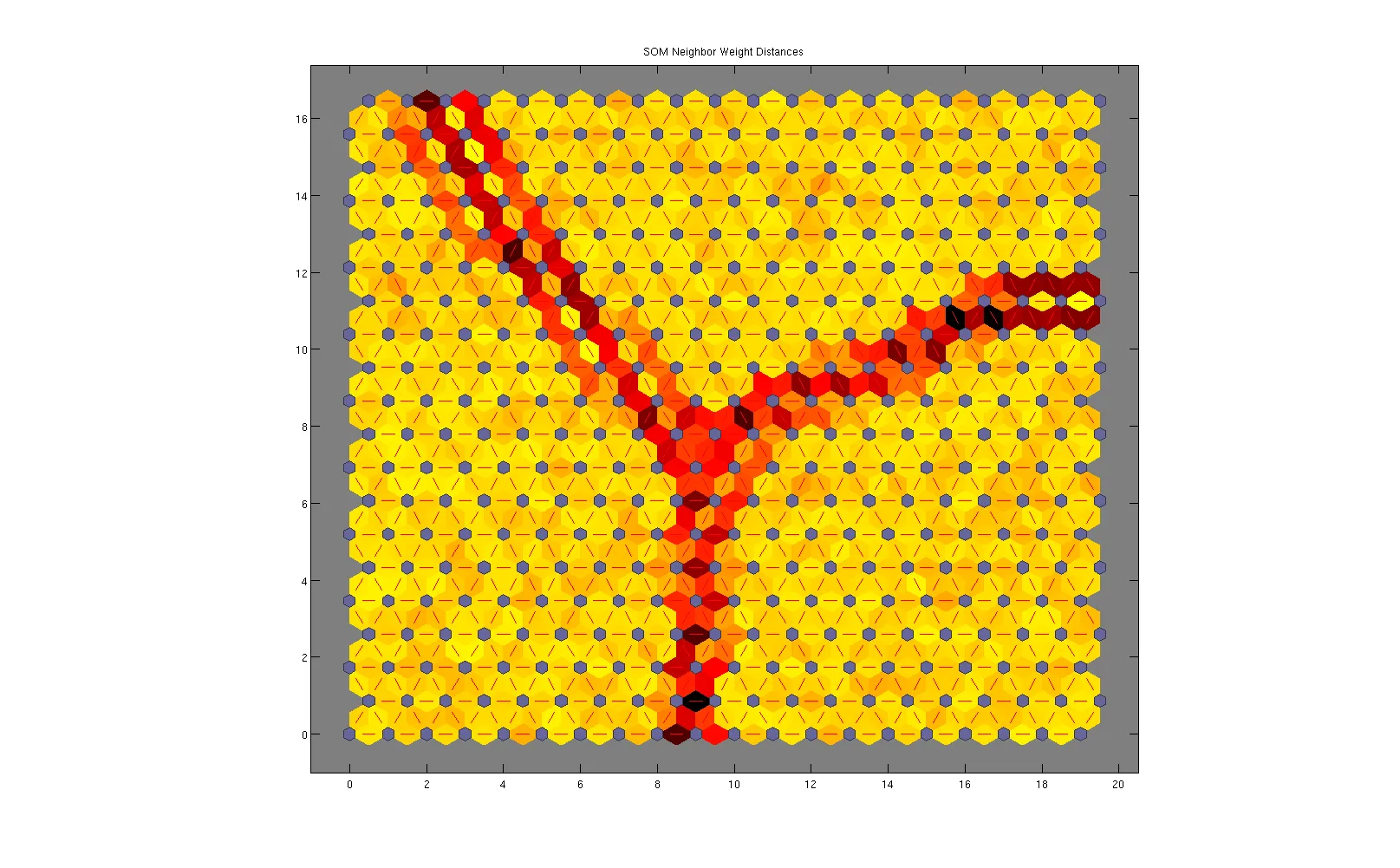
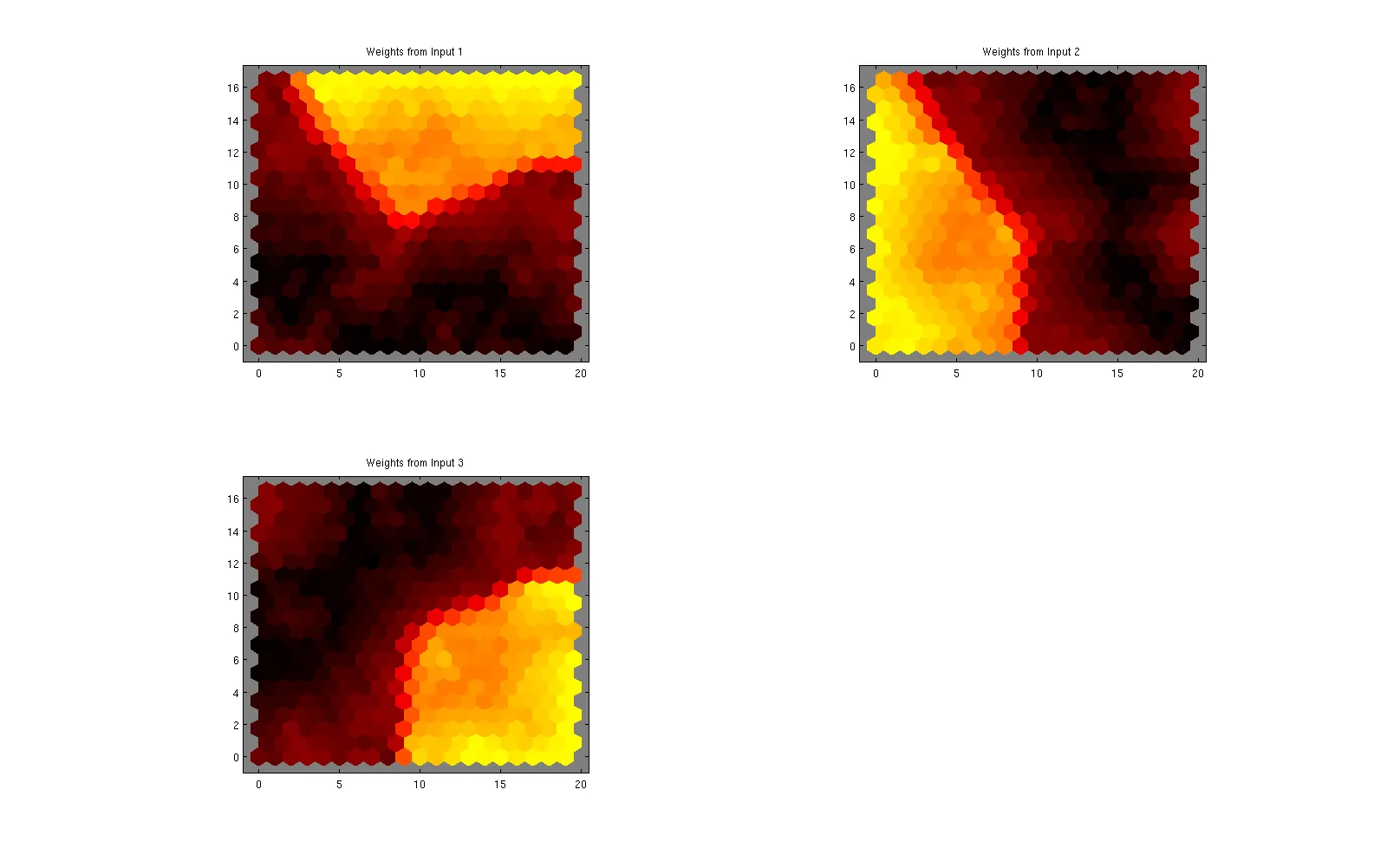 当您查看邻居距离和命中映射时(分别为图2和图3),这更加明显:
当您查看邻居距离和命中映射时(分别为图2和图3),这更加明显:
在图2中,节点与其相邻节点之间距离越远(通过节点权重和相邻节点的权重之间的欧几里得距离计算)的颜色越深。因此,我们可以看到高度相关节点的三个区域。我们可以使用此图像并对其进行阈值化,以获得三个不同区域(三个聚类),然后获取平均权重。
在图3中,介绍了数据集中每个节点标签的样本数量。可以看出,之前的三个区域呈现出相对均匀的样本分布(考虑到三个簇具有相同数量的样本是有意义的),而界面节点(分割三个区域的节点)则没有映射任何样本。同样,我们可以使用此图像并进行阈值化,以获得三个不同区域(三个聚类),然后获取平均权重。
因此,通过一些简单的后处理,您可以将数据集从 3000x3 减少到一个 3x3 的矩阵。

- ASantosRibeiro
3
谢谢您提供简单而详细的解释。虽然我在使用Python,但我能更好地理解这个概念。但是我对最后两个数字有点困惑。 - Pooja
谢谢你,这真的非常有帮助。 - Pooja
@Pooja 如果这有帮助,请在问题左上方接受它。 - ASantosRibeiro
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接